
An Ultimate Guide on Duplicate Content in SEO

What Is Duplicate Content?
Duplicate content appears on multiple web pages. This problem usually arises when the same content is published on different websites with different domains. However, the distribution of duplicate content on several pages of the same resource can sometimes reduce the effectiveness of your SEO strategy.
Duplicate texts filled with keywords can be very harmful. However, you can find yourself in a difficult situation owing to the massive borrowing of images and videos.
However, we communicate with the same words, authors come up with similar ideas, and even original movies may contain footage from other films. Moreover, different pages of the site often include contact info and legal terms of service that cannot be changed. Consequently, we have to deal with a certain percentage of duplicates.
How much unique content should a web page contain? Search engines don’t give a specific answer, and experts offer different figures. Tony Wright, a reputable author in Search Engine Journal, gives one of the most realistic figures. According to him, a website should have at least 30% of content that cannot be found elsewhere. This applies both to other pages of the resource and other domains.

Is it easy? Not really. Let us remind you that some details are duplicated within the site. These are subheadings, contacts, and navigation menus. They account for up to 20% of the total page content. Moreover, most resources cite other pages. Even online stores can take advertising messages from manufacturers. Additionally, a certain percentage of text can be borrowed accidentally, simply because authors use the same source of info. Furthermore, this figure increases over time as new competitors will constantly appear in your market niche.
Therefore, even with a careful approach to content management, the share of duplicates ranges from 25% to 50%. Hence, you will need to continuously monitor the quality of your site’s content. You should order copywriting, develop multimedia elements, update pages and add new materials periodically. You cannot stop in this process. Otherwise, you risk losing control of the situation.
Why Does Content Duplication Matter?
Imagine you go to a supermarket and see two identical products from different manufacturers that are almost equal in price. Which one is better? Which one will you buy? Such a choice leads most people to a dead end. In most cases, they refuse both products and find an alternative. This is exactly what search engines do when they detect content duplication.
If the pages on two resources duplicate each other, the crawler will not search for the original page. It will simply divide the points given for authority, link building, and academic value between them. Consequently, all duplicates will get a lower ranking and will take lower positions in SERPs. If the situation is forced by other violations, the case may even end in a refusal to index, although such decisions are rarely made in practice.
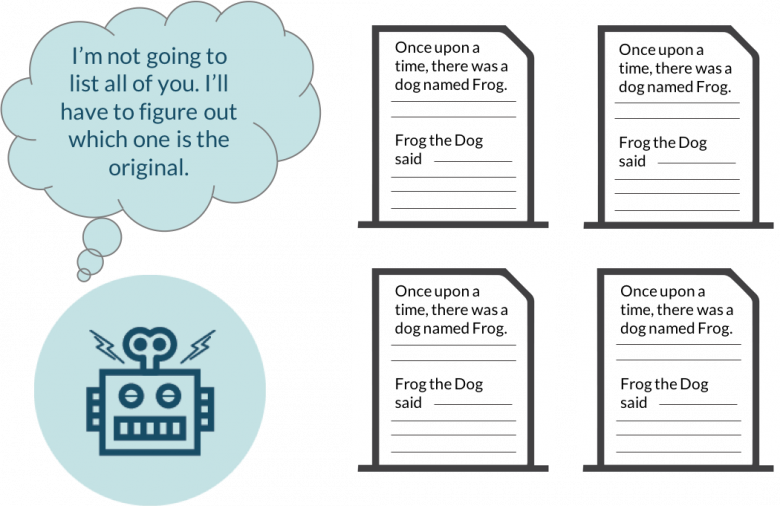
Of course, Google, Bing, and their competitors monitor not only the site content. However, it can lead to a paradoxical situation when borrowed materials get a higher ranking. This happens when competitors have better technical optimization. Therefore, monitoring the Web for duplicate content is a breath of life for the owner of any resource.
How Does Duplicate Content Impact SEO?
Search engine ranking drop is a long-term result that you can get by ignoring the problem for a long time. At the same time, duplicate content issues can start immediately. Let’s talk about them in more detail.
Burns Crawl Budget
This term refers to the time that Google takes to index a website. If it contains a lot of pages, including duplicate content, the search engine may not index the most valuable sections. To fix this problem, you will have to manually disable duplicate indexing and wait for the next processing of the resource. During this time, you may lose your rankings, visitors, and profits.
Fewer Indexed Pages
It rarely happens, but sometimes, a duplicate content penalty results in the page`s exclusion from the search engine. The consequences are clear. This is a huge loss for a successful business. You can fix the problem by updating the content or disputing the decision. In any case, you will have to spend a lot of time on it and wait for the next indexing.
Backlink Dilution
If the search engine sees several identical pages and cannot identify the original, it divides the ranking points among all the contenders. This means that the network of external links that you have been building for several months will work both for you and your competitors. You must admit that this is not a very pleasant prospect. We can compare it with industrial espionage when other companies get your trade secrets for free.

Decreased Organic Traffic
It is the final result that stems from the previous points. The longer you ignore duplicate content issues, the lower your search engine rankings will become, and fewer visitors will be able to find your site. That’s why it’s important to identify and fix SEO strategy drawbacks as soon as possible.
Main Causes of Duplicate Content Issues
Everything may seem quite obvious here. Someone has created a duplicate website hoping to take advantage of a competitor’s popularity and make an instant profit. However, in practice, things are not that simple. Moreover, there are purely technical reasons that may not be obvious to an SEO specialist for a long time.
Scraped or Copied Content
When it comes to a personal blog, it is quite easy to control its content. It is a much more complicated task for commercial resources. For example, online stores often automatically parse product characteristics from manufacturers’ websites. A marketing agency can copy offers from third parties or business partners unchanged. This is the most common reason for duplicate content.
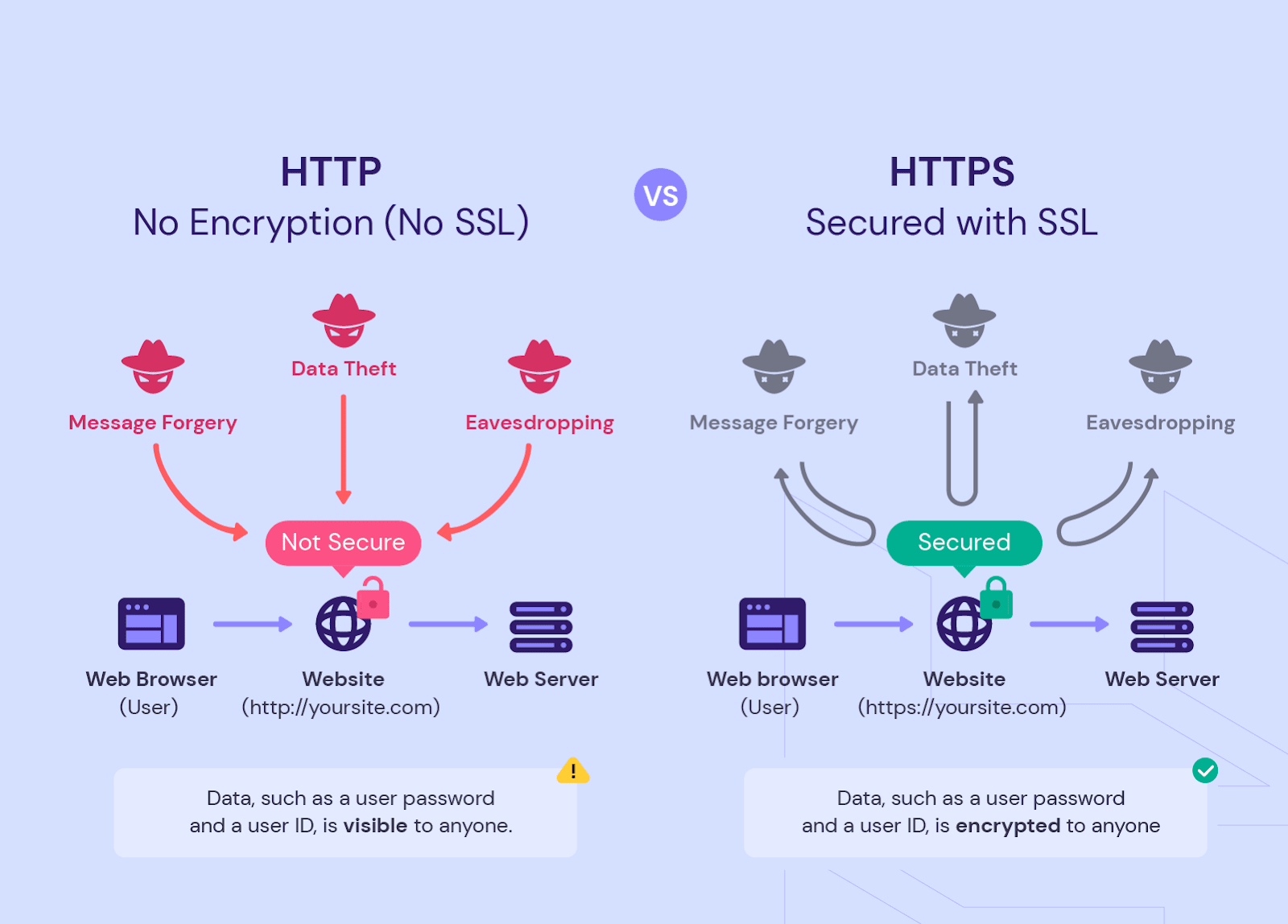
HTTP vs. HTTPS or WWW vs. Non-WWW Pages
It is considered a sign of good manners to have a website that works with the secure HTTPS protocol and has no WWW prefix. However, this is true for new websites. Old sites often have HTTP and WWW versions in addition to the main ones. If they completely duplicate the content and are indexed by search engines, it will reduce the SEO strategy`s effectiveness.
Content Syndication
Some sites focus on reposts. They attract users by collecting all the captivating materials on a particular topic in one place. At the same time, authors build a network of links and strengthen their SEO rank. However, blind website duplication can lead to severe penalties from Google. Therefore, content syndication should be entrusted only to trusted partners.
URL Variations
Users can access the same page with different URLs on large websites. For example, they can access it from external resources, by using filters in the online store catalog, or by following a referral link. This situation usually takes place when you use a standardized CMS. It simplifies navigation but creates additional risks.
Order of Parameters
This problem stems from the previous one. Some CMSs do not monitor the way a page is selected in the catalog or navigation menu. As a result, you can get the same content using the /?size=500&color=3 and /?color=&3size=500 filters. The search engine will index both variants and detect duplication.
Paginated Comments
Popular articles and product cards receive hundreds and thousands of comments. Displaying them on one page is a bad idea from the point of view of technical optimization. In this case, the site will work much slower. Most CMSs have a pagination function, which means separating comments into several pages. However, this function creates several versions of the URL that differ only in the reviews.

Mobile-friendly and AMP URLs
Duplicate content in Google often appears when optimizing a website for smartphones and tablets. Alternative pages are created for them, which are also indexed. At the same time, they are almost identical in content to the desktop versions.
Attachment Image URLs
WordPress and other popular CMSs create a separate page for an uploaded image by default. It has little to no SEO value but creates the risk of duplicate content and lower website rankings. To avoid this situation, you should provide a link to the original location of the image.
Tag and Category Pages
These concepts are often used to search in blogs, online stores, and other resources. However, you need to be very responsible when structuring your site. Tags and categories that are too close in meaning can be recognized as duplicate pages. The same concerns limited filtering. If only one item falls into a tag or category, it will duplicate the page of that article or product card.
Print-friendly URLs
This type of duplicate content in SEO usually appears in online catalogs, libraries, and law firm websites. Trying to improve UX, they immediately prepare documents for printing. However, this results in a page duplicate that differs only in format and not in content.
Case-sensitive URLs
It is a problem that is not easy to diagnose. The secret is that Google distinguishes between uppercase and lowercase letters in links. If your site gives the same answer to queries with different cases, the search engine will consider it two duplicate pages.
Session IDs
Online stores mostly use them. They temporarily store such history of user actions as filling a cart or viewing products. This system usually uses cookies. However, some CMSs create new URLs by default, fully duplicating content an unlimited number of times.
Parameters for Filtering
You should always know where the user comes from. It will help you build the right sales funnel and make the best commercial offer. However, adding parameters for filtering URLs leads to the creation of troublesome links to the same pages that can be indexed by search engines.
Trailing Slashes vs. Non-trailing-slashes
Historically, a link ending in “/” provides access to a folder but not a specific web page. This is no longer relevant today. However, search engines consider links with and without trailing slashes to be different pages.
Index Pages (index.html, Index.php)
It is necessary for the correct website functioning and the correct processing of links by search engines. However, it is not always displayed as the main URL. It causes page duplication and creates cloning content within one resource.
Indexable Staging/Testing Environment
Website updates and adding of new features are often done live. By placing test pages on the server, you can immediately test them in real time. However, remember to delete the previous versions or exclude them from search indexing. Due to simple inattention, you may leave new pages without organic traffic.
How to Find Duplicate Content on a Website
A manual search is not the best idea. Even if you know what duplicate content is and what causes it, you may always miss small technical issues. When you have hundreds of pages on your site, the task becomes Mission Impossible.
The best option is to use tools for a comprehensive SEO audit. You can use the following apps:
- MOZ
- SEMRush
- SERPStat
- Sitechecker
- Ahrefs
We should note that these are paid tools. The basic subscription costs from $50 to $100 per month. However, they will provide you with a lot of useful features, including keyword research, link management, and technical audit.
To find similar content on the Web, you can use free plagiarism checkers. For example, these are Copywritely, Copyscape, and Grammarly. In their basic versions, they offer a limited number of checks. To increase the number of checks and activate the continuous monitoring option, you will need to sign up for a paid subscription.
Common Website Duplicate Content Solutions
Of course, you should consider each case individually. Sometimes, two seemingly similar problems can have different technical details. However, here is a list of solutions that will help you get rid of 80% of unintentionally duplicate content.
301 Redirect
It is easier than restructuring and more effective than other methods. If you have duplicate content on the website owing to the presence of HTTP and HTTPS versions, as well as pages with and without the WWW prefix, you should direct traffic to the correct page. When the crawlers see this code, they will follow the link and index only the content that you specify for them.

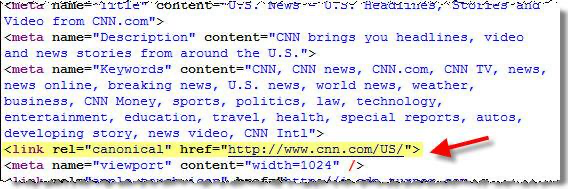
Rel=“canonical”
It points to the page that contains the original content. It instructs search bots to ignore all copies of the page, including those optimized for printing and mobile devices created during development and testing. Google representatives have frequently pointed out that 301 redirects and the canonical tag are the most effective ways to manage the indexing of your pages.
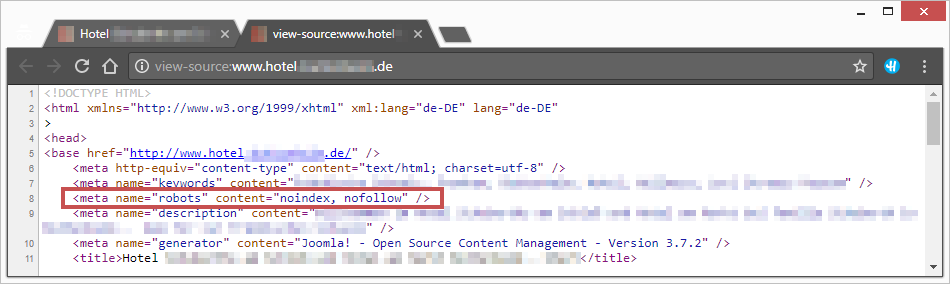
Meta Robots Noindex
When the search engine sees this tag, it will ignore the page. However, you should keep in mind that it can still follow the links on it if you have not blocked this feature. This method allows you to block several troublesome pages on your website. However, you shouldn’t get too carried away with it. Google engineers say that it increases the response time of the resource and the crawling duration.
Preferred Domain and Parameter Handling in Google Search Console
Log in to this service, select the project, and go to the site settings. Select the domain you want to index. For example, you can ignore HTTP or WWW versions of pages. Previously, the app allowed you to specify individual crawling settings for each URL. However, this feature disappeared in 2022. The disadvantage of this method is that it only gives a command to Google search robots. All other systems will continue to index your pages with duplicate content.

Consolidating Pages
For example, you have published several posts with similar but not identical content. Owing to its low uniqueness, it may not be ranked high in search results. To fix this problem, simply merge all the pages into one. Write one text and add unique theses from each article to it. All the rest can be highlighted or blocked for search crawlers. As a result, your page ranking in the SERP will be increased significantly.
Duplicate Content – How Harmful Is It?
No matter how you slice it, no page can be 100% unique. Therefore, search engines are quite loyal to the presence of the same content in different sections of the site. Up to a certain point. If a resource contains several pages that repeat each other by 100%, or you borrowed content from your competitor, you will have problems. At first, it will result in both a ranking and an organic traffic drop. Ignoring the warnings and continuing such a risky policy, your resource can fall out of search indexing.
Consequently, you should fix the problem as soon as possible. To find it in time, you should use universal SEO audit services or specialized tools. In most cases, the most common fixes for duplicate content will be the solution. These are redirects, tags, and commands to search crawlers. If this doesn’t help, you should change the content by ordering copywriting and developing multimedia elements.
FAQ
What Is Duplicate Content?
This is text or multimedia content that appears on other pages of the same site or other domains on the Web.
Is Duplicate Content Harmful?
Experts state that 30-60% of unique content can be considered the norm, depending on specific conditions. Only large fragments of text or plenty of images borrowed from another source will be harmful.
Does Google Have a Duplicate Content Penalty?
The search engine does not set direct restrictions. However, if there are several copies of the same page, it automatically divides the ranking points between them, lowering their positions. Google rarely refuses to index your pages. It is usually done only in case of numerous violations of the rules.
What Is the Most Common Fix for Duplicate Content?
You can identify the original page using the Rel=“canonical” tag, set up automatic redirects, block indexing of non-unique content, consolidate content, or select the correct domain in Google Search Console.





More Like This

Guide On Finding Your Brand's Tone Of Voice
