
What Is Robots Txt And How To Use It To Improve Your SEO

Hundreds of individual factors influence search engines’ ranking results, and technical optimization occupies an important place among them. If a project has problems with loading speed or duplicate pages, its potential may be left unlocked.
Immediately after launching a site, webmasters usually create a map, close service pages from indexing, and add meta tags. But sometimes, they forget about important tasks that are better to complete in the first turn.
Even beginners know what robots.txt is, but not all website owners pay enough attention to working with it. In some cases, the file is generated with the help of SEO plugins and then abandoned for good. This can lead to indexing and ranking issues in the future, so it’s best to keep an eye on the status of the file.
What Is a Robots.txt File?
Robots.txt is a service document containing rules for search robots. Search engine spiders take it into account when crawling pages and making URL indexing decisions.
The file should be considered as a tool to reduce the load on the project server rather than a way to quickly block access to service pages. It works similarly to the nofollow tag for links — search engines may consider the rules although it is not guaranteed.
Usually, search engines follow existing directives but make a decision based on a combination of factors depending on the case. For example, additional analysis algorithms are activated when the file has conflicting lines.
A well-designed robots.txt can be beneficial for improving positions in SERP, but it is only one of the thousands of bricks needed for a website to rank well. Therefore, you should not get too obsessed with updating the file.
How exactly does it work?
You need to delve into technical nuances to understand how the file works. It won’t take much time — the basics can be learned from Google’s webmaster help section in a few hours.
Search engine robots perform two main operations — they scan webpages’ content and index them. Robots.txt is something like a signpost. It shows the spiders a route to follow when scanning a web resource, but it is impossible to know in advance whether the bots will follow the tips.
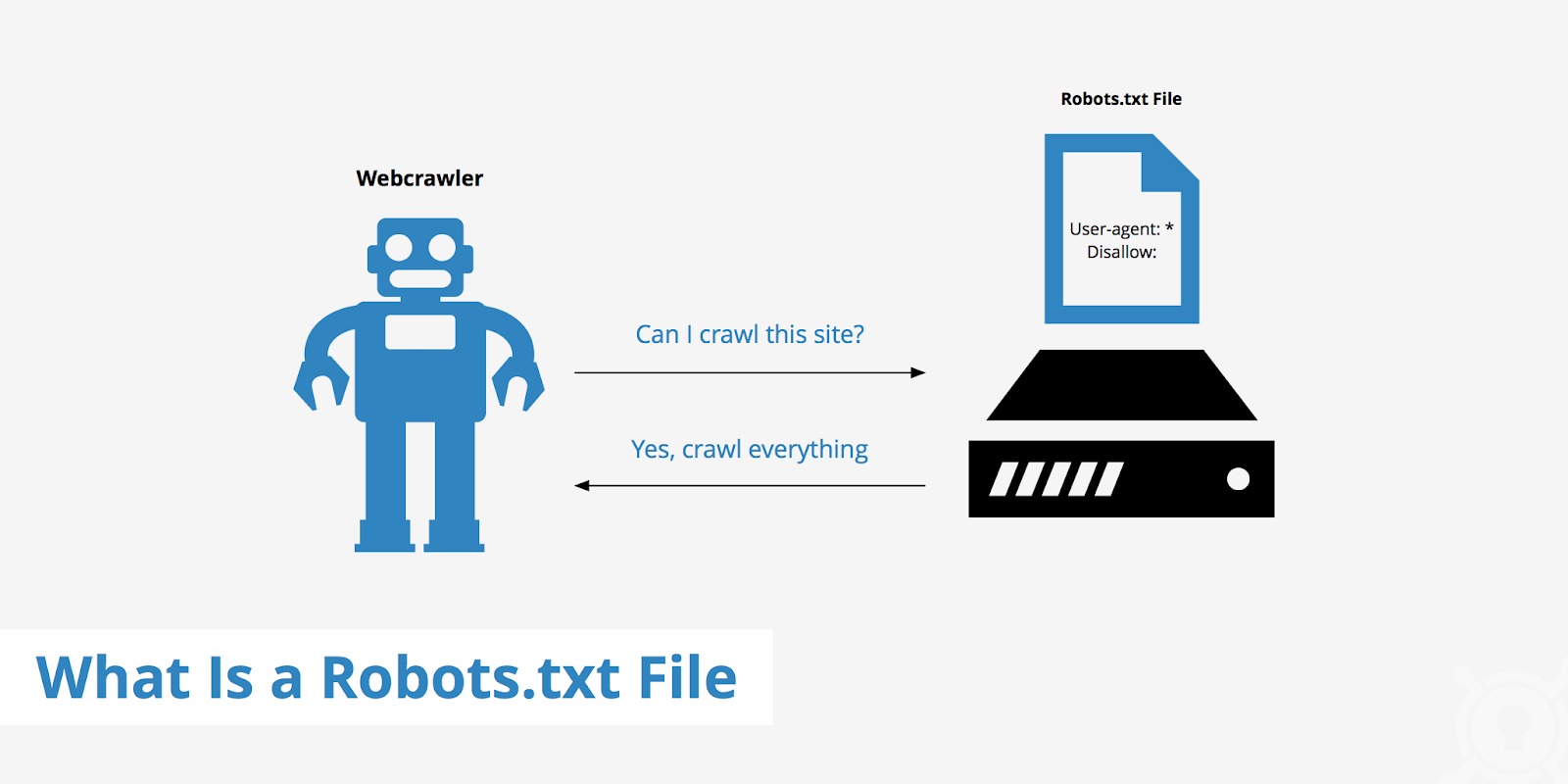
Before embarking on crawling, search spiders usually analyze the contents of the robots.txt file to understand which pages the project owner does not want to index. They may or may not follow the rules.
The file is often regarded as an effective tool to prevent indexing, but that’s not true. If search engine algorithms think a page has content helpful for users, it can be indexed.
It is also necessary to understand that scanners of different services use unique scenarios when working with the syntax of this technical file. Therefore, extra addresses may get into SERP if you do not create your own rules for a specific user agent.
To be 100% protected from adding a page to search results, you need to block access to it using .htaccess or other server tools. In this case, you won’t need to specify the URL in the robots txt for Google.
Why Do You Need Robots.txt?
Some believe there is no need to create a robots.txt file in 2023. This is actually a wrong statement since this file is used by search spiders, which is a good motivation to spend time creating the document.
Robots.txt isn’t a panacea for preventing pages from indexing, but it’s usually pretty good at showing URLs that should not be crawled. This saves the spiders’ time and the server’s resources.
Also, a notification will appear in Google Search Console if the document is not listed in the root directory. That’s not a critical problem, but it is better to avoid giving the algorithms an extra reason to pay more attention to the project.
There is no need to create this service file for resources promoted outside of search engines. This applies to SaaS and other services with a permanent audience. Each webmaster makes their own decision as to performing SEO tasks, but additional traffic won’t hurt in any case.
Crawl budget optimization
The crawl budget is a limit for crawling a resource’s pages. Google robots scan the addresses of each project differently, so it’s not possible to understand in advance how quickly they will crawl all the URLs.
Optimizing the page crawl budget involves closing service sections in robots.txt for Googlebot. Thanks to this, search engine spiders will not waste resources scanning redundant addresses, and the indexing of important URLs can be accelerated.
The crawl budget is a very unpredictable thing, but the optimization can positively affect the crawling speed, and, therefore, you should not ignore this task.
Blocking duplicates and non-public pages
Duplicates provoke link juice dilution and worsen page ranking. For example, if a site has 50 duplicate URLs receiving traffic from search engines, it is better to get rid of them.
Also, every site has pages that should not be visible to users: an administrative panel, an address with private statistics, etc. It is better to block access to them at the server level and then additionally specify them in robots.txt.

Preventing resource indexing
In addition to pages, you can use directives in the service file to ban media content scanning. These can be images, PDF files, Word documents, and other content types.
Usually, all it takes to prevent files with media content from appearing in search results is blocking them in robots.txt. But this doesn’t work in some cases, and if Google’s or other services’ algorithms make a different decision, it will be possible to bypass it only by completely banning the files at the server level.
Limiting access to images or scripts in the service file takes minimum time. You need to find robots.txt and use special wildcard characters for all the documents to fall under the created rules.
A high-quality robots.txt file with no errors is a bonus to a project. If competitors have problems with technical optimization, it can give an opportunity to outperform them in the fight for traffic.
How to Find Robots.txt?
You can find the service file in a few seconds in the root directory of a site at domain.com/robots.txt. If it is a subdomain, you only need to change the first part of the address.
Sometimes there are problems with overwritten files, so it is better to prohibit this operation through an FTP manager. If you manually disable content alteration, robots.txt for SEO will work at full blast.
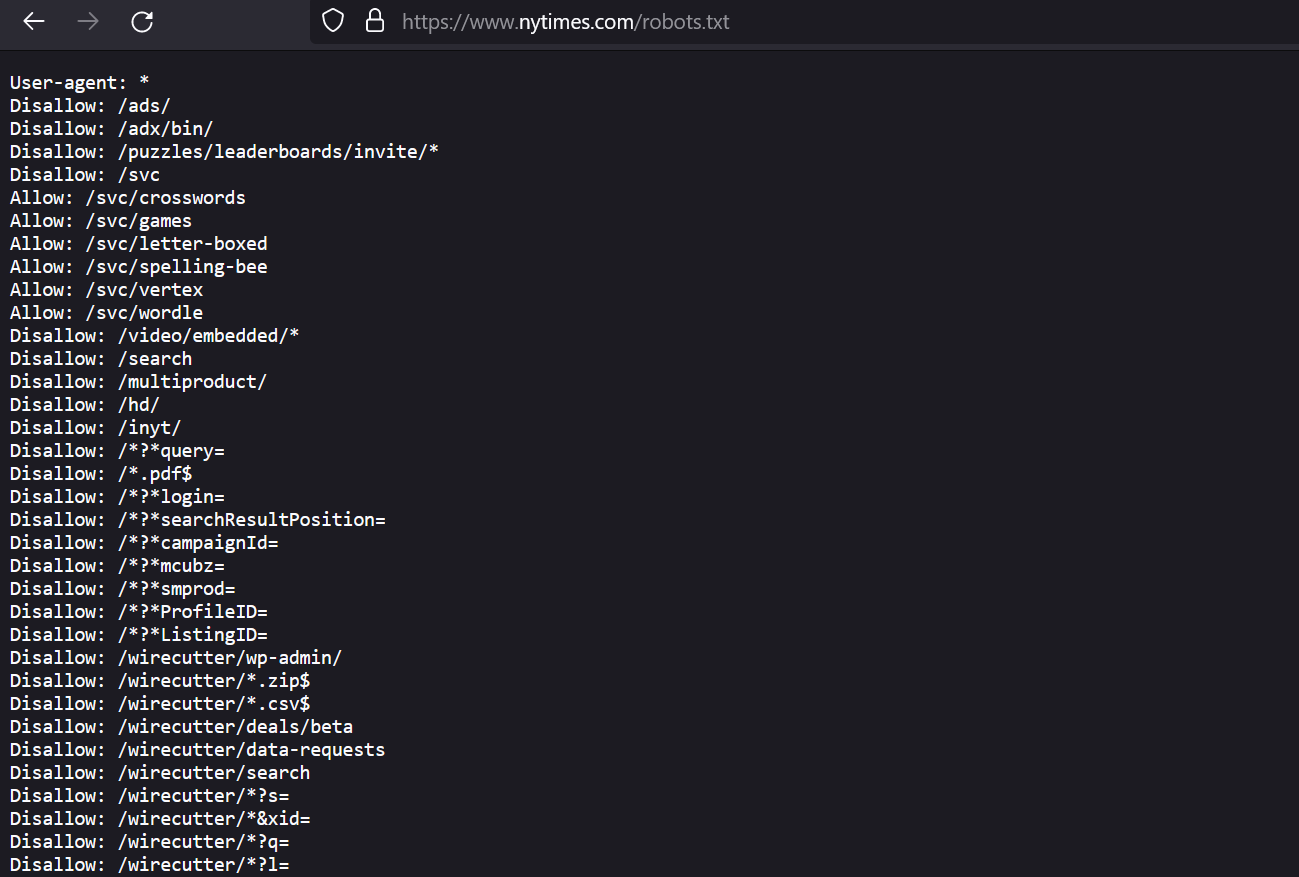
SEO plugins in popular CMSs can often affect the robots.txt structure. In this case, the templates created by a webmaster are not protected from disappearing, and the site owner may not notice it for a long time if the file is overwritten.
You also need to make sure the file is accessible to robots and use specialized analysis tools for this purpose. There will be no problems with access in cases where the server’s response is 200.
Syntax and Supported Directives
Newbies in SEO may find creating robots.txt a difficult task, but actually, there is nothing complicated about it. If you know what operations the # symbol or regular expressions do, you can use them without any problems.
Robots.txt has a specific syntax:
- The slash (/) tells the robots what exactly to block from scanning. It can be a page or a large section with thousands of addresses.
- The asterisk (*) helps generalize URLs in a rule. For example, you need to add an asterisk to close all pdf pages in an address from scanning.
- The dollar sign ($) is attached to the final part of an URL. It is usually used to prevent files or pages with a certain extension from being scanned.
- The hash sign (#) helps to navigate the file. It is used to mark comments that search engines ignore.
For a beginner, it is better to dismantle the syntax immediately after learning what the robots.txt file is. You can start learning from directives, but syntax is also important.
There are only 4 main directives to know. You can make the same rules for all user agents without wasting extra time creating separate rules for each of them, but you should consider the fact that the crawling process is different for each spider.
User-agent
Search engines and online scanners have their own user agents. With their help, a server can understand which robot visited a site, which makes it easy to follow its behavior through log files.
The user-agent directive is used in robots.txt to indicate exactly which rules apply to a particular spider. When the pattern is the same for all spiders, an asterisk is used in the row.
There can be at least 50 user-agent directives in the file, but it is better to make 3-5 separate lists. And make sure to add comments for convenient navigation since this prevents getting confused in a large amount of data.

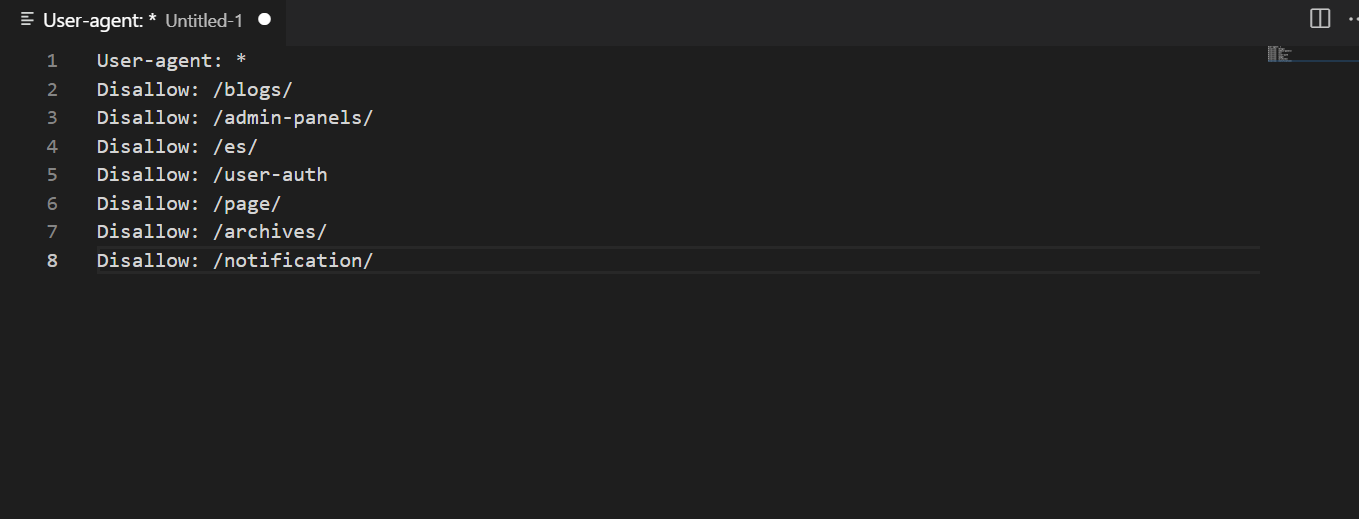
Disallow
This directive is used when you want to exclude pages or sections from a list of addresses to be scanned. It is often used for duplicates, service URLs, and pagination.
The Disallow rule must be combined with the slash symbol. Search spiders will ignore the rule if a path to an address is not specified. Therefore, it is better to make sure the syntax is correct.
You should use this directive carefully, as there is a risk that important addresses may not be included in search results. Conduct additional analysis before saving the changes in the file.
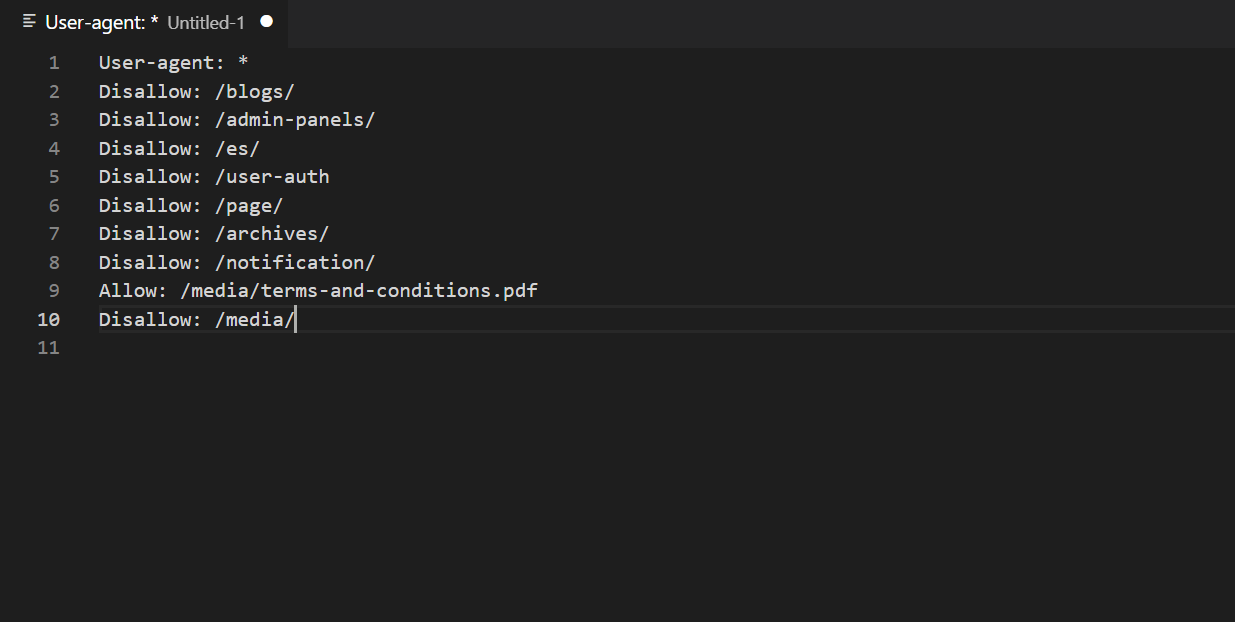
Allow
One of the best practices for robots.txt is to use the Allow directive. It allows scanning pages or entire sections and is used in combination with Disallow to create an optimal file structure.
You also need to be careful with the Allow rule so that service pages and other URLs eroding the link profile within a project do not get into search results. Slashes correctly placed in addresses ensure the required pages are covered.
When a file has conflicting crawl rules, the number of characters is decisive for Google, so the longest rule will be followed.
Sitemap
This directive is considered optional, but experienced SEO specialists recommend using it. It indicates the location of the sitemap address and should be specified at the beginning or at the end of the document.
If a map is added through Google Search Console, you can do without specifying the URL in robots.txt, but indicating it will do no harm. The sitemap directive is included in 99% of public robots.txt templates.
Maintaining proper syntax in the file ensures correct content scanning by search engine robots, which has a positive effect on technical optimization and adds points to the overall project ranking.
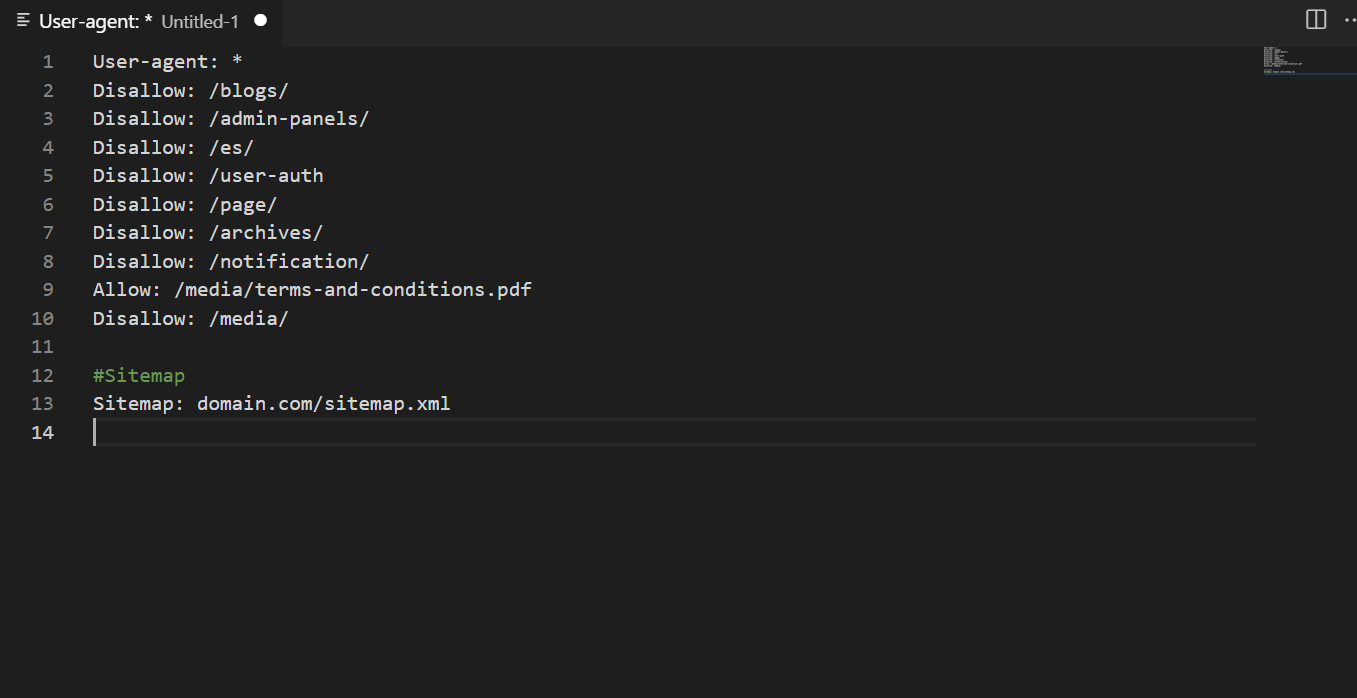
Unsupported Robots.Txt Directives for Googlebot
Outdated instructions for robots can be seen on the Web, and beginners make mistakes relying on them. This will not interfere with normal indexing and will not cause problems with page ranking, but it is better to adapt the file to the correct format.
If you look at the technical files of projects with many years of history, you can often find outdated directives in them. By themselves, they do not cause damage, so they are ignored by search engines. But for perfect optimization of the site, it is better to get rid of them.
Crawl-delay
Previously, this directive fully conformed to the correct robots.txt format. Currently, Google does not support it, so it makes no sense to limit scanning speed in the file — bots will ignore these lines.
Bing still recognizes the Crawl-delay directive, so you can specify it for the appropriate user agent. However, it will be difficult to find a reason to use it if you receive no traffic from Bing.
Noindex
Google’s help center has never mentioned that someone can prevent content from being indexed using the Noindex directive. But some webmasters are still doing it in 2023.
Alternatively, you can disable scanning with Disallow and use technical tools to restrict access at the server level. A combination of these methods will allow you to get the desired result.
Nofollow
This directive doesn’t work either, along with the similar tag that limits passing on link juice. There is currently no effective way to close links from weight transfer.
Creating a robots.txt file cannot prevent link indexing. Google robots can easily handle even encrypted links that are not visible in the source code.
Another obsolete directive is Host — this command was used to indicate the main mirror of a site. The 301 redirect has been working instead of it for many years.
How to Create a Robots.Txt File?
Robots.txt is a plain text file, which should be placed in the main directory of a site. It can be created using Notepad in Windows or standard file manager tools on your server.
Make sure the file has the correct extension. Otherwise, search engine robots will not be able to parse the content, and an access error message will appear in Search Console.
If necessary, you can use a standard template from open sources, but you need to make sure it contains no conflicts. You can use the default structure on a rolling basis only upon checking it.
Create a file named Robots.txt
When newbies to SEO ask how to create a robots.txt file, the answer is not hard to plumb. You do not need to install specialized software on your computer — Notepad will do the job perfectly.
Make sure to save your changes after each document update. Since there is no autosave in the standard program, part of the data may be lost during the editing process, and you will have to start all the work from the beginning.
Add rules to the file
The correct way to design rules in robots.txt is by combining user agents and using comments. It makes no sense to specify rules for the same robot in different parts of the file.
Make sure there are no conflicts when adding rules since they result in search engines acting at their own discretion. However, there are no guarantees the directives will be followed even when everything is specified correctly.
Check the syntax
Correct robots.txt for SEO is a file with no syntax errors. Most often, beginners make mistakes in writing directives. For example, they write Disalow instead of Disallow.
You also need to carefully monitor the use of slashes, asterisks, and hash signs. It is easy to get confused in these symbols and close or open unnecessary pages for scanning. You can check the syntax using various online services.
Download the file
After creating the file structure and saving the final version on the computer, all that remains is to upload it to the server. Only the root directory is suitable for this.
We recommend limiting the possibility of overwriting the file, because the syntax may be affected when your CMS and plugins are updated. Although it’s not a frequent problem, it can be eliminated only in this way.
Test and debug if necessary
The work does not end with creating the robots.txt file. You still need to make sure there are no errors in it. You can solve the task both manually and with the help of online scanners.
For example, you can use the tool, which does a good job of analyzing syntax. Its report displays information about the errors found and the availability status.
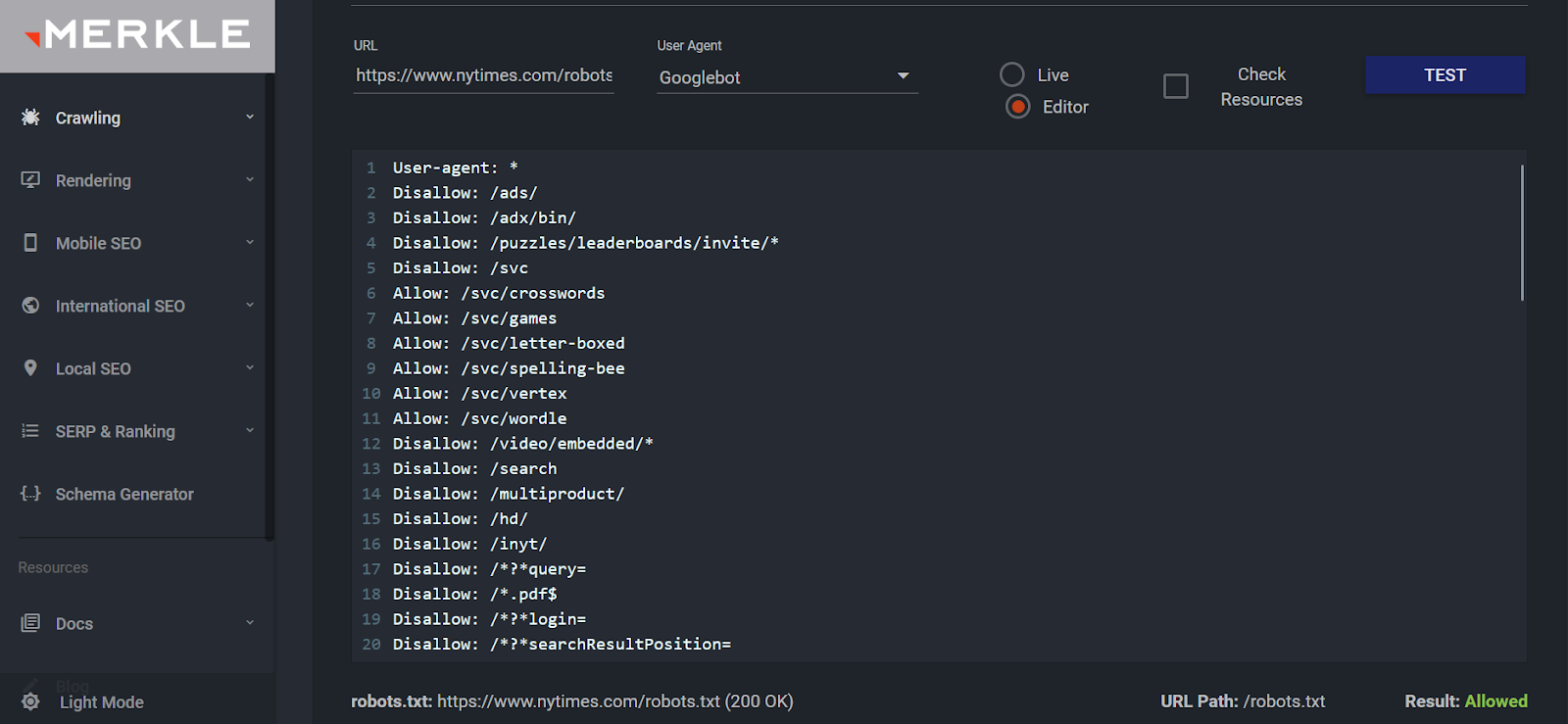
You can learn about crawling and indexing issues in Google Search Console, but it is better to prevent them and get the maximum benefit from technical optimization.
Best Practices for Working with Robots.Txt
Working with this service file is usually not difficult, but there can be problems with creating a perfect set of rules for large project promotion.
Optimizing robots.txt takes time and requires relevant experience. Online scanners allow you to save resources, but they will not cover absolutely all your needs. Therefore, you cannot do without manual analysis.
Tips for effective work with robots.txt will be useful to webmasters of all experience levels. Sometimes, even a small mistake can destroy a large amount of work done, and it needs to be spotted promptly.
Use a new line for each directive
When beginners start working with the syntax of robots.txt, they often make one mistake — they write the rules in one line. This poses a problem for search robots.
To eliminate negative consequences, you need to begin a new line for each rule. This helps the spiders and eases navigation for a specialist who will update the file.
Bad:
User-agent:* Disallow: /admin-panel
Fine:
User-agent:*
Disallow: /admin-panel
Use each User-agent only once
When novice SEO specialists ask what to include in robots.txt, they often overlook the proper use of user agents. Finding a list of popular spiders isn’t a problem, but there is more to it.
If you create 50 rules for one robot, they should be combined. Search robots will have no problem with merging them without your help, but it is better to do it yourself even for the ease of using the file.
Bad:
User-agent: Googlebot
Disallow: /admins-panel
….
User-agent: Googlebot
Allow: /blog
Fine:
User-agent: Googlebot
Disallow: /admins-panel
Allow: /blog
Create separate Robots.txt files for different subdomains
When promoting large projects with thousands of pages and dozens of subdomains, you need to optimize each directory separately. The fact is that each subdomain is a new site from a search engine’s point of view.
Robots.txt can be template-based, but it must be placed in the root directory of all promoted subdomains. This rule does not apply to technical subdomains closed to users.
Be specific to minimize possible mistakes
The owners of online projects often have problems with closing access to pages and sections. This is usually caused by improper use of slashes and other wildcards.
Almost every webmaster knows what robots txt is, but many of them make critical mistakes when it comes to creating rules, which can affect indexing and ranking.
For example, you want to restrict access to pages prefixed with /es because the directory is under development. In this case, the result is determined by the correct use of the slash sign.
Bad:
User-agent: *
Disallow: /es
Fine:
User-agent: *
Disallow: /es/
In the second case, all pages belonging to the corresponding directory are restricted. And in the first case, there may be problems with all addresses having the “es”.
Use comments to explain your Robots.txt file to people
While search engine spiders ignore any strings that use the hash symbol, comments allow webmasters to navigate the document structure. Therefore, you should definitely devote your attention to them when learning what robots.txt is in SEO.
The lack of comments is not bad when there are 10-20 lines in a document. But if it has hundreds of them, it is better to write tips for yourself and SEO specialists who will work on the project in the future.
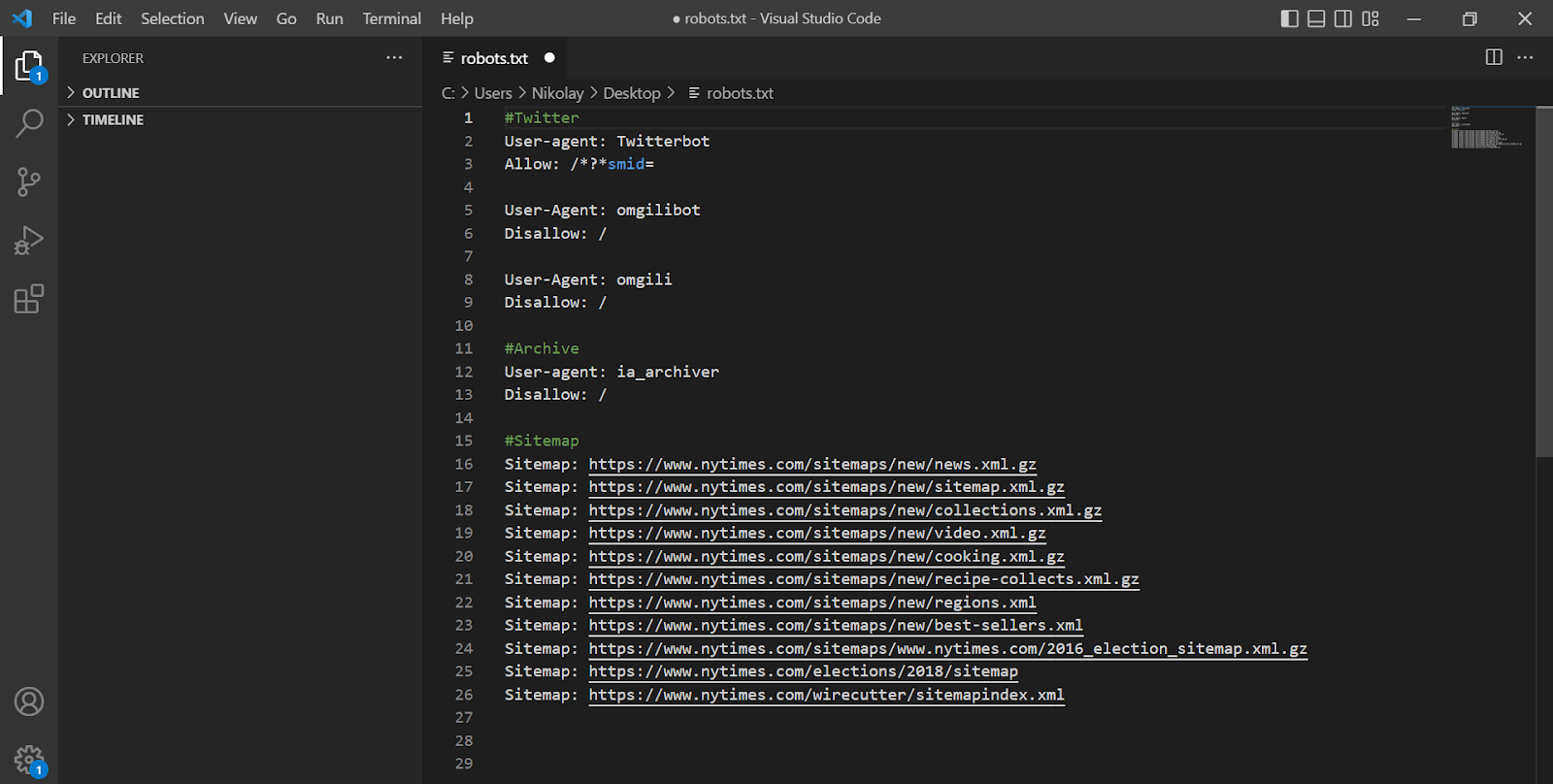
Life hacks on robots.txt optimization can also be spotted on reputable projects that do not have problems with search traffic. Most of them can be found in the PRPosting directory. It is enough to collect a list of 5-10 resources for analysis and look at their file versions.
Also, you can chat with SEO specialists in your personal account with the service when discussing link placement. Thus, you can seamlessly combine internal and external optimization.

Conclusions
Many people know how to find robots.txt, but not all of them are aware of how to work with the file correctly. It doesn’t take much time to learn the basics of file optimization, so it’s worth spending it, including constantly improving your knowledge.
What is a robots.txt file?
This is a technical file that contains rules for scanning website pages. Search engines use it to understand which sections are not prioritized for indexing.
How to create a robots.txt file?
This can be done using Notepad, an FTP manager, or specialized services. In each case, the result will be the same.
How to find robots.txt?
Unlike a sitemap, the file must be placed in the root directory. There is no use in the document if it lies in another place.
What is the maximum size of a robots.txt file?
The approximate limit is 500 KB. The size depends on the number of rows, but it is difficult to exceed the limit if optimization measures are taken.







