
Гайд по дублированному контенту в SEO

Что такое дублированный контент?
Дублированный контент появляется на нескольких веб-страницах. Обычно проблема возникает, когда одинаковые материалы публикуют на разных сайтах с разными доменами. Однако иногда распространение одинакового контента на нескольких страницах одного ресурса также снижает эффективность поисковой оптимизации.
Наибольшее влияние имеют дубликаты текста, наполненного ключевыми словами. Однако вы можете оказаться в сложной ситуации и по причине массового заимствования изображений и видео.
Но мы общаемся одинаковыми словами, к авторам приходят схожие идеи и даже оригинальные фильмы могут содержать кадры из других кинолент. К тому же разные страницы сайта часто включают контактные данные и юридические условия обслуживания, изменять которые невозможно. Так что нам всегда приходится иметь дело с определенным процентом дубликатов.
Какое количество абсолютно уникального контента должна содержать веб-страница? Сами поисковики не дают конкретного ответа, а эксперты называют разные цифры. Один из самых реалистичных показателей приводит Тони Райт, регулярно публикующий свои исследования в Search Engine Journal. Он говорит, что на сайте должно быть не менее 30% контента, который не встречается в других местах. Это относится как к другим страницам ресурса, так и к другим доменам.

Легко? Не совсем. Напомним, что некоторые элементы дублируются внутри сайта — подзаголовки, контакты, меню навигации. На них приходится до 20% всего контента страницы. Большинство ресурсов также приводят цитаты с других страниц — даже интернет-магазины могут принимать рекламные обращения производителей. Еще определенный процент текста заимствуется совершенно случайно — просто потому, что авторы используют один источник информации. К тому же эта цифра растет со временем, ведь в вашем сегменте будут постоянно появляться новые конкуренты.
Поэтому даже при внимательном подходе к контент-менеджменту доля дубликатов колеблется от 25 до 50%. А это значит, что нужно постоянно контролировать качество наполнения сайта — заказывать копирайтинг и разработку мультимедийных элементов, периодически обновлять страницы и добавлять новые материалы. Останавливаться в этом процессе нельзя, иначе есть риск потерять контроль над ситуацией.
Почему дублированный контент имеет такое значение?
Представьте, что вы пришли в супермаркет и видите два одинаковых товара разных производителей, которые почти не отличаются по стоимости. Какой из них лучше? Какой вы купите? Подобный выбор заводит в тупик большинство людей — чаще всего они отказываются от обоих товаров и находят альтернативу. Именно так поступают и поисковые системы, когда видят дупликацию контента.
Если страницы на двух ресурсах будут копировать друг друга, робот не будет искать оригинал. Он просто разделит между ними баллы, выставляемые за авторитетность, развитие сети ссылок и академическую ценность. В результате, все дубликаты получат более низкий рейтинг и опустятся на странице поисковой выдачи. Если ситуация отягощена другими нарушениями, дело может закончиться даже отказом в индексации, хотя на практике такое решение принимается очень редко.
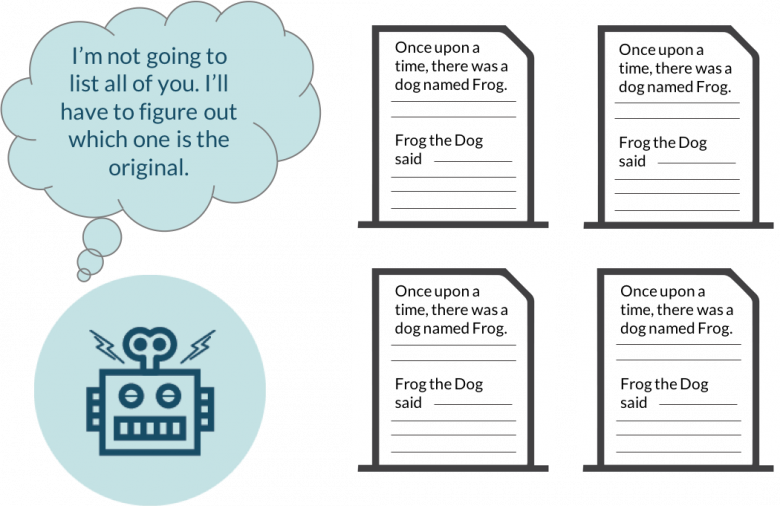
Конечно, Google, Bing и их конкуренты учитывают не только контент на сайте. Но это может привести к парадоксальной ситуации, когда заимствованные материалы получают более высокий рейтинг. Такое случается, когда у конкурентов лучшая техническая оптимизация. Поэтому мониторинг интернета на предмет копий — жизненная необходимость для владельца любого ресурса.
Как именно дублированный контент влияет на SEO?
Снижение позиций в поисковой выдаче — это долгосрочный результат, который можно получить, если долго игнорировать проблему. Но проблемы с дублированным контентом могут начаться и немедленно. Расскажем о них подробнее.
Сжигание бюджета краулинга
Под этим термином понимают промежуток времени, выделяемый Google на индексацию сайта. Если он содержит много страниц, включая дублированный контент, то наиболее ценные разделы могут так и не попасть в поисковую систему. Чтобы устранить такую проблему, придется вручную выключать индексацию дубликатов и ждать последующей обработки ресурса. За это время вы можете потерять рейтинг, посетителей и прибыль.
Меньшее количество индексированных страниц
Это случается очень редко, но иногда штрафом за дублированный контент становится исключение страницы из поисковой системы. Последствия ясны — для успешно работающего бизнеса это колоссальные убытки. Проблема может быть устранена обновлением содержимого или обжалованием решения. Однако в любом случае придется потратить на это немало времени и ждать следующей индексации.
Разделение массива ссылок
Если поисковая система видит несколько одинаковых страниц и не может определить оригинал, то она разделяет рейтинговые баллы между всеми претендентами. Это означает, что система внешних ссылок, которую вы выстраивали в течение нескольких месяцев, будет работать не только на вас, но и конкурентов. Согласитесь, не слишком приятная перспектива — это сравнимо с промышленным шпионажем, когда другие фирмы бесплатно получают ваши производственные секреты.

Снижение органического трафика
Конечный результат, вытекающий из предыдущих пунктов. Чем дольше вы игнорируете проблемы дублированного контента, тем ниже ваши позиции в поисковых системах и все меньше посетителей находит ваш сайт самостоятельно. Именно поэтому важно выявлять и устранять недостатки SEO-стратегии как можно быстрее.
Основные причины дублирования контента
Кажется, все очевидно. Кто-то сделал дубликат веб-сайта, рассчитывая воспользоваться популярностью конкурента и получить мгновенную прибыль. Однако на практике не все так просто. Есть и сугубо технические причины, которые могут долгое время быть неочевидными для SEO-специалиста.
Автоматическое или ручное копирование контента
Когда речь идет о личном блоге, контролировать его наполнение достаточно просто. С коммерческими ресурсами все гораздо сложнее. К примеру, интернет-магазины часто занимаются автоматическим парсингом характеристик с сайтов производителей. А маркетинговое агентство может копировать предложения своих подрядчиков или бизнес-партнеров в неизменном виде. Это самая распространенная причина появления дублированного контента.
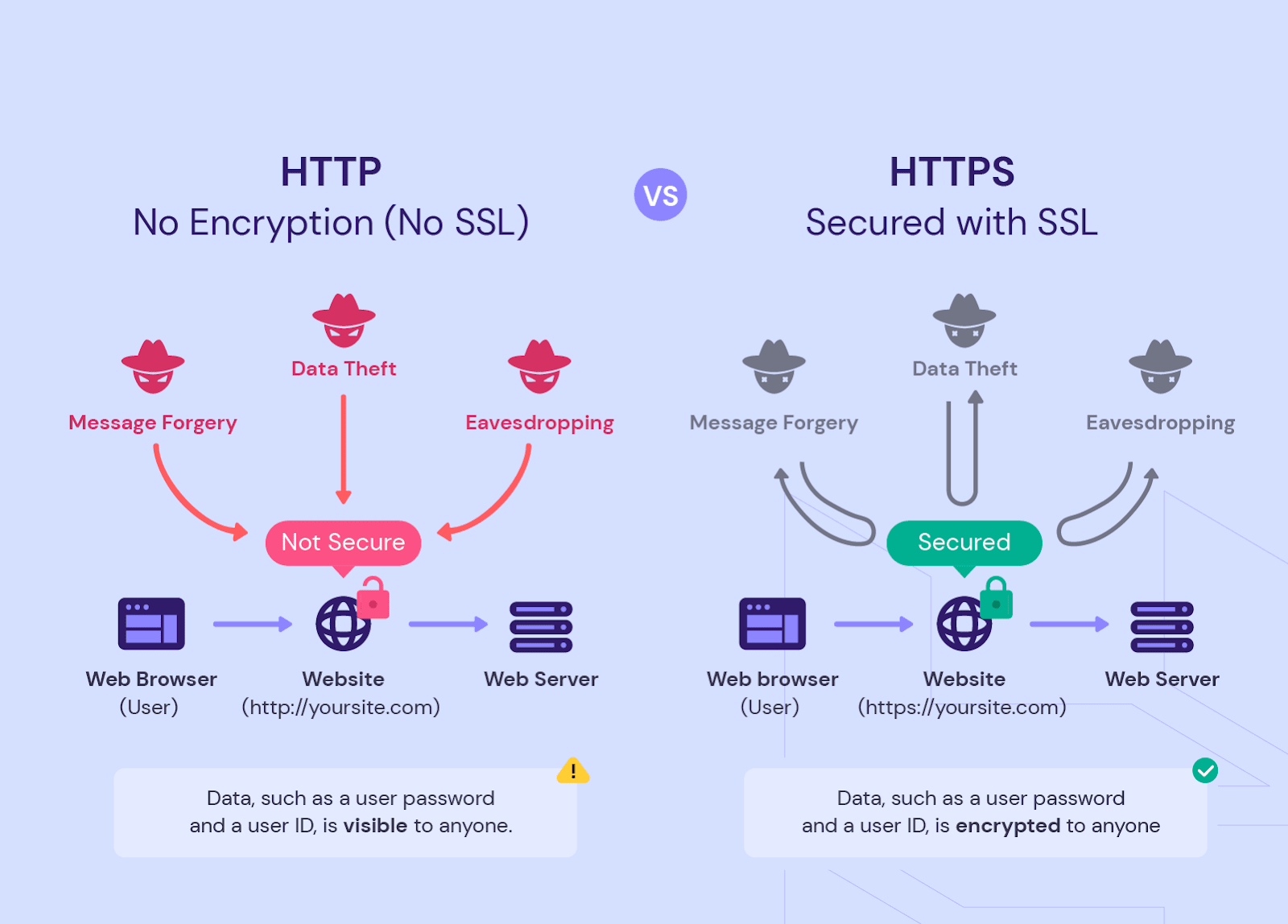
Разница между HTTP и HTTPS, адресами с префиксом WWW и без него
Хорошим тоном считается сайт, который работает с защищенным протоколом HTTPS и не имеет префикса WWW. Однако это актуально для новых ресурсов. Старые сайты часто имеют HTTP- и WWW-версии в дополнение к основным. Если они полностью дублируют контент и индексируются поисковиками, это может снизить эффективность SEO-стратегии.
Синдикация контента
Некоторые сайты специализируются на репостах. Они собирают в одном месте все интересные материалы по определенной тематике, получая внимание зрителей. В то же время авторы перестраивают сеть ссылок и усиливают свои позиции в поисковой оптимизации. Однако слепая дупликация веб-сайтов может стать причиной штрафов со стороны Google. Поэтому синдикацию контента следует доверять только проверенным партнерам.
Вариации URL
На больших веб-сайтах пользователь может получать одну и ту же страницу по разным адресам. Например, переходить на нее с внешних ресурсов, с помощью фильтров в каталоге интернет-магазина и по реферальной ссылке. Такая ситуация, как правило, возникает при использовании стандартизированной системы управления контентом. Она упрощает навигацию, но создает дополнительные опасности.
Порядок параметров
Эта проблема вытекает из предыдущей. Некоторые CMS не фиксируют способ отбора страницы в каталоге или в меню навигации. В результате, вы можете получить тот же контент с помощью фильтров /?size=500&color=3 и /? color=&3size=500. Поисковая система попытается индексировать оба варианта и обнаружит копирование.
Группировка комментариев
Популярные статьи и карточки товаров набирают сотни, если не тысячи реакций. Показывать их на одной странице — плохая идея с точки зрения технической оптимизации. Сайт будет работать гораздо медленнее. Большинство CMS имеют функцию пагинации — разбивание комментариев на несколько страниц. Однако стандартно она создает несколько версий URL, отличающихся только отзывами.

Ссылки на мобильные версии и AMP-страницы
Дублированный контент в Google часто возникает при оптимизации сайта под смартфоны и планшеты. Для них создаются альтернативные страницы, тоже попадающие в индексацию. При этом по контенту они почти не отличаются от десктопных версий.
Ссылки на изображения
Стандартно WordPress и другие популярные CMS создают отдельную страницу для загруженной картинки. Она почти не имеет SEO-ценности, но создает угрозу дублирования контента и снижения рейтинга сайта. Чтобы избежать такой ситуации, лучше давать ссылку на оригинальное расположение изображения.
Теги и категории
Эти понятия часто используются для поиска в блогах, интернет-магазинах и других ресурсах. Однако к структурированию сайта нужно подходить очень ответственно. Слишком близкие по содержанию теги и категории могут распознаваться как дублированные страницы. То же касается узкой сортировки. Если в тег или категорию попадает только один элемент, они будут дублировать страницу этой статьи или карточки товара.
URL, оптимизированные для печати
Обычно такой тип дублированного контента в SEO появляется в онлайн-каталогах, библиотеках и на сайтах юридических фирм. Пытаясь улучшить UX, они сразу готовят документы к печати. Однако это приводит к копированию страницы, отличающейся только форматом, а не содержимым.
Чувствительность к регистру URL
Неприятная проблема, сложная для диагностики. Секрет заключается в том, что Google различает прописные и строчные буквы в ссылках. Если ваш сайт дает одинаковый ответ на запросы с разным регистром, поисковая система сочтет это двумя дублированными страницами.
Идентификаторы сессий
В большинстве своем они используются интернет-магазинами. Временно сохраняют историю действий пользователя, например, наполнение корзины или просмотр товаров. Обычно в такой системе используются файлы Cookie. Однако некоторые CMS стандартно создают новые URL, полностью дублируя контент неограниченное количество раз.
Параметры трекинга
Всегда важно знать, откуда пришел посетитель. Это поможет правильно построить воронку продаж и сделать лучшее коммерческое предложение. Однако добавление параметров трекинга в URL приводит к созданию нежелательных ссылок на те же страницы, которые могут индексироваться поисковыми системами.
Слеш в конце URL
Исторически сложилось так, что ссылка, которая заканчивалась на «/», предоставляла доступ к папке, а не конкретной веб-странице. Сегодня это уже неактуально. Однако поисковики считают ссылки с конечными слешами и без них разными страницами.
Страница index
Нужна для корректной работы веб-сайта и для правильной обработки ссылок поисковиками. Однако она не всегда выводится в качестве основного URL. Это приводит к дупликации страниц и клонированию контента в пределах одного ресурса.
Индексация среды разработки и тестирования
Работы по обновлению сайта и добавлению функций часто проводятся «вживую». Размещая пробные страницы на сервере, вы можете сразу протестировать их в реальных условиях. Но не забывайте удалять предыдущие варианты или исключать из поисковой индексации. По банальной невнимательности новые страницы могут остаться без органического трафика.
Как найти дублированный контент на сайте?
Ручной поиск — не лучшая идея. Даже если вы знаете, что такое дублированный контент и в чем причины его появления, всегда можно упустить мелкие технические моменты. Когда количество страниц на сайте измеряется сотнями, задача вообще переходит в категорию Mission Impossible.
Оптимальный вариант — использование инструментов для комплексного SEO-аудита. Свои приложения предлагают:
- MOZ;
- SEMRush;
- SERPStat;
- Sitechecker;
- Ahrefs.
Следует заметить, что это платные наборы инструментов. Базовая подписка на них стоит от $50 до $100 в месяц. Но в них вы получаете много полезных функций, включая поиск ключевых слов, управление массивом ссылок и технический аудит.
Для поиска подобного контента в интернете можно также воспользоваться условно-бесплатными сервисами проверки уникальности. Например, это Copywritely, Copyscape и Grammarly. В базовом варианте они предлагают ограниченное количество поисков. Чтобы увеличить объем запросов и активировать функцию непрерывного мониторинга, необходимо оформить платную подписку.
Самые распространенные способы решения проблем с дублированным контентом
Конечно, каждый случай следует рассматривать индивидуально. Иногда две похожие внешне проблемы могут иметь разные технические детали. Но мы приведем список решений, которые помогут избавиться от 80% непреднамеренно дублированного контента.
301 Redirect
Легче реструктуризации, эффективнее других способов. Если у вас есть дублированный контент на веб-сайте из-за наличия HTTP- и HTTPS-версий, а также страниц с префиксом WWW и без него, направьте трафик на правильную страницу. Увидев этот код, поисковые роботы перейдут по ссылке и будут индексировать только тот контент, который вы укажете для них.

Rel=”canonical”
Указывает на страницу, содержащую оригинальный контент. Дает поисковым ботам команду игнорировать все ее копии, в том числе оптимизированные для печати и мобильных девайсов, созданные при разработке и тестировании. Представители Google неоднократно отмечали, что перенаправление по коду 301 и тег канонической страницы — наиболее эффективные способы управления индексацией.
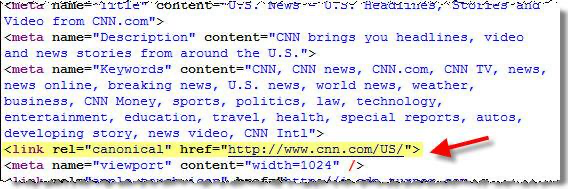
Meta robots noindex
Увидев этот тег, поисковая система будет игнорировать страницу. Однако помните, что она все еще может переходить по ссылкам в ней, если вы не заблокировали эту функцию. Этот способ позволяет заблокировать несколько нежелательных страниц на сайте. Однако слишком увлекаться им не стоит. Инженеры Google говорят, что он увеличивает время отклика ресурса и продолжительность краулинга.
Настройка домена в Google Search Console
Авторизуйтесь в этом сервисе, выберите нужный вам проект и переходите к настройкам сайта. Выберите именно тот домен, который вы хотите индексировать. Например, можно игнорировать HTTP- или WWW-версии страниц. Ранее в приложении можно было указывать индивидуальные настройки краулинга для каждого URL, однако в 2022 году эта функция исчезла. Минус такого способа заключается в том, что он дает команду только поисковикам Google. Все остальные системы продолжат индексировать ваши страницы с дублированным контентом.

Консолидация контента
Например, вы публиковали несколько сообщений с похожим, но не одинаковым контентом. Из-за низкого показателя уникальности они могут иметь плохой рейтинг в поисковой выдаче. Чтобы устранить эту проблему, просто объедините все страницы в одну. Напишите один текст, добавив в него уникальные тезисы по каждой статье. Все остальные можно выделить или заблокировать для роботов. Результатом будет существенный рост страницы в SERP.
Дублированный контент — насколько это плохо?
Как ни крути, ни одна страница не может быть уникальной на 100%. Поэтому поисковики достаточно лояльно относятся к наличию одинакового контента в разных разделах сайта. До определенного предела. Если ресурс содержит несколько страниц, повторяющих друг друга на 100%, или вы позаимствовали контент у своего конкурента, начинаются проблемы. Сначала это понижение рейтинга и падение размера органического трафика. Игнорируя предупреждения и продолжая столь рискованную политику, можно вообще выпасть из поисковой индексации.
Поэтому проблему следует устранять как можно быстрее. Чтобы обнаружить ее вовремя, воспользуйтесь универсальными службами SEO-аудита или специализированными инструментами. В большинстве случаев решением будут распространенные способы борьбы с дублированным контентом — перенаправление, теги и команды поисковым роботам. Если это не помогает, следует изменить наполнение, заказав копирайтинг и разработку мультимедийных элементов.
Часто задаваемые вопросы
Что такое дублированный контент?
Текст или мультимедийное содержимое, которое встречается на других страницах одного сайта или других доменах в интернете.
Насколько вреден дублированный контент?
Эксперты говорят, что нормой можно считать 30–60% уникального содержания в зависимости от конкретных условий. Вредны только большие фрагменты текстов или значительные объемы изображений, заимствованные в другом источнике.
Штрафует ли Google за неуникальный контент?
Поисковая система не устанавливает прямых ограничений. Однако при появлении нескольких копий одной страницы она автоматически делит между ними рейтинговые баллы, снижая их позиции. Отказ в индексации применяется очень редко — обычно так поступают только в случае многочисленных нарушений правил.
Какие самые популярные способы борьбы с дублированным контентом?
Вы можете определить оригинальную страницу с помощью тега Rel=”canonical”, назначить автоматическое перенаправление, заблокировать индексацию неуникального контента, консолидировать контент или выбрать правильный домен в Google Search Console.





Так же читайте

Что такое реферальная ссылка и как она работает

Что такое голос бренда и как его определить
