
Що таке файл Robots.txt і як ним правильно користуватися

Зазвичай одразу після запуску сайту вебмайстри створюють мапу, закривають від індексації службові сторінки та додають метатеги. Але інколи вони забувають про важливі завдання, які краще закрити насамперед.
Навіть новачки знають, що таке robots.txt, але не всі власники сайтів приділяють увагу роботі з ним. В деяких випадках файл генерують за допомогою SEO-плагінів і забувають про його існування. Це може призвести до проблем з індексацією та ранжування у майбутньому, тому краще стежити за станом файлу.
1. Що таке файл Robots.txt?
Robots.txt — це службовий документ, який містить правила для пошукових роботів. Сканери пошуковиків враховують його, коли їм потрібно обійти сторінки та ухвалити рішення про індексацію URL.
Файл варто розцінювати як інструмент зниження навантаження на сервер проєкту, а не як спосіб швидкого блокування доступу до службових сторінок. Він працює аналогічно з тегом nofollow для посилань — пошукові роботи можуть враховувати правила, але гарантії немає.
Зазвичай пошукові системи виконують наявні директиви, але в кожному випадку рішення ухвалюється на основі сукупності факторів. Наприклад, коли у файлі є суперечливі рядки, активуються додаткові алгоритми аналізу.
Якісно скомпонований robots.txt може принести користь у SERP, але він лише одна цеглинка з тисяч необхідних для хорошого ранжування. Тому не варто занадто зациклюватися на постійному оновленні файлу.
1.1. Як саме він працює?
Щоб розібратися, як працює robots, потрібно заглибитись у технічні нюанси. На це не знадобиться багато часу — базові знання можна отримати за кілька годин з довідкового розділу Google для вебмайстрів.
Роботи пошукових систем виконують дві головні операції — сканують вміст сторінок та індексують їх. Robots.txt — це щось на кшталт дороговказу. Він показує спайдерам маршрут, за яким можна сканувати ресурс. А ось чи дотримуються роботи підказок, заздалегідь дізнатися неможливо.
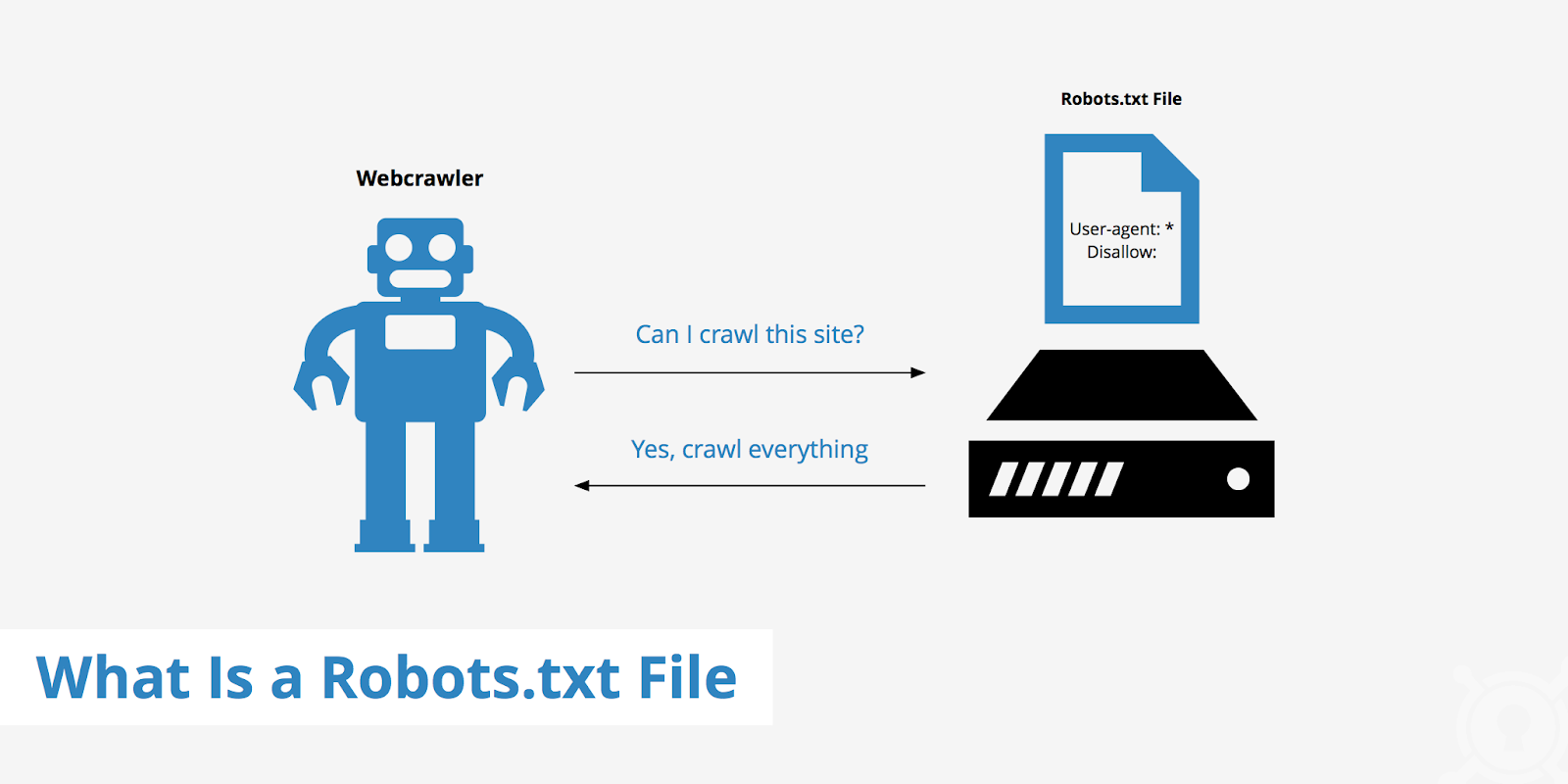
Зазвичай перед скануванням ресурсів пошукові павуки аналізують вміст файлу robots.txt, щоб зрозуміти, які сторінки власник проєкту не хоче додавати до індексу. Вони можуть дослухатися до правил або ні.
Robots часто розцінюють як ефективний інструмент для заборони індексації, але це не так. Якщо алгоритмам пошуковика здасться, що на сторінці є корисний для користувачів контент, вона може потрапити в індекс.
Також необхідно розуміти, що сканери різних сервісів працюють із синтаксисом технічного файлу за унікальним сценарієм. Тому, якщо не створити власні правила для конкретного юзер-агента, до видачі можуть потрапити зайві адреси.
Щоб на 100% захиститися від додавання сторінки у видачу, потрібно закрити до неї доступ за допомогою .htaccess чи інших серверних інструментів. Тоді URL не потрібно буде вказувати у robots txt для Google.
2. Навіщо потрібен Robots.txt?
Є думка, що у 2023 році створювати файл robots немає потреби. Насправді це хибне твердження, тому що цей файл використовується пошуковими спайдерами. А це стимул для того, щоб витратити час на створення документа.
Robots.txt не є панацеєю для заборони індексації сторінок, але він зазвичай вправно показує пошуковикам адреси, які не варто обходити. Це заощаджує час спайдерів і ресурси сервера.
Також якщо документа немає у кореневій директорії, надійде сповіщення в Google Search Console. Нічого критичного в проблемі немає, але краще не давати алгоритмам зайвого приводу для підвищеної уваги до проєкту.
Не потрібно створювати службовий файл для ресурсів, які просуваються за межами пошукових систем. Це стосується SaaS та інших сервісів із постійною аудиторією. Рішення про необхідність виконання SEO-завдань кожен вебмайстер ухвалює самостійно, але додаткові переходи не будуть зайвими в будь-якому випадку.
2.1. Оптимізація краулінгового бюджету
Краулінговий бюджет — це ліміт на сканування сторінок ресурсу. Роботи Google по-різному сканують адреси кожного проєкту, тому заздалегідь не вдасться зрозуміти, наскільки швидко вони обійдуть всі URL.
Оптимізація бюджету на сканування сторінок передбачає закриття службових розділів у robots.txt для Googlebot. Якщо це зробити, павуки пошуковика не витрачатимуть ресурси на обхід зайвих адрес, й індексація важливих URL може пришвидшитися.
Краулінговий бюджет — дуже непередбачувана річ, але оптимізація robots може позитивно вплинути на швидкість обходу сторінок спайдерами. Тому не варто ігнорувати це завдання.
2.2. Блокування дублікатів і непублічних сторінок
Дублі провокують розмивання посилальної ваги та погіршують ранжування сторінок. Наприклад, якщо на сайті 50 дублікатів URL, який отримує переходи з пошуковиків, краще їх позбутися.
Також на кожному сайті є сторінки, що не повинні потрапляти на очі користувачам: адміністративна панель, адреса з приватною статистикою та ін. Доступ до них краще заблокувати на рівні сервера і додатково вказати у robots.

2.3. Запобігання індексації ресурсів
Крім сторінок, можна використати директиви у службовому файлі для відмови від сканування медіаконтенту. Це можуть бути зображення, PDF-файли, Word-документи та інший вміст.
Блокування у robots зазвичай достатньо, щоб файли з медіаконтентом не з’явилися в пошуковій видачі. Але в деяких випадках можуть виникати проблеми. Якщо алгоритми Google чи інших сервісів ухвалять інше рішення, обійти його можна буде лише за допомогою повної заборони на рівні сервера.
На обмеження доступу зображень чи скриптів у службовому файлі потрібно мінімум часу. Треба знайти robots.txt та використати спеціальні символи підстановки, щоб під створені правила потрапили всі документи.
Якісний robots без помилок — це бонус у скарбничку проєкту. Якщо у конкурентів є проблеми з технічною оптимізацією, це може стати однією з можливостей обійти їх у боротьбі за трафік.
3. Як знайти Robots.txt?
Знайти службовий файл можна за кілька секунд у кореневій директорії сайту за адресою domain.com/robots.txt. Якщо йдеться про субдомен, потрібно змінити лише першу частину адреси.
Іноді виникають проблеми з перезаписом файлу, тому краще заборонити операцію через FTP-менеджер. Якщо вручну відключити можливість зміни вмісту, robots.txt для SEO працюватиме на повну потужність.
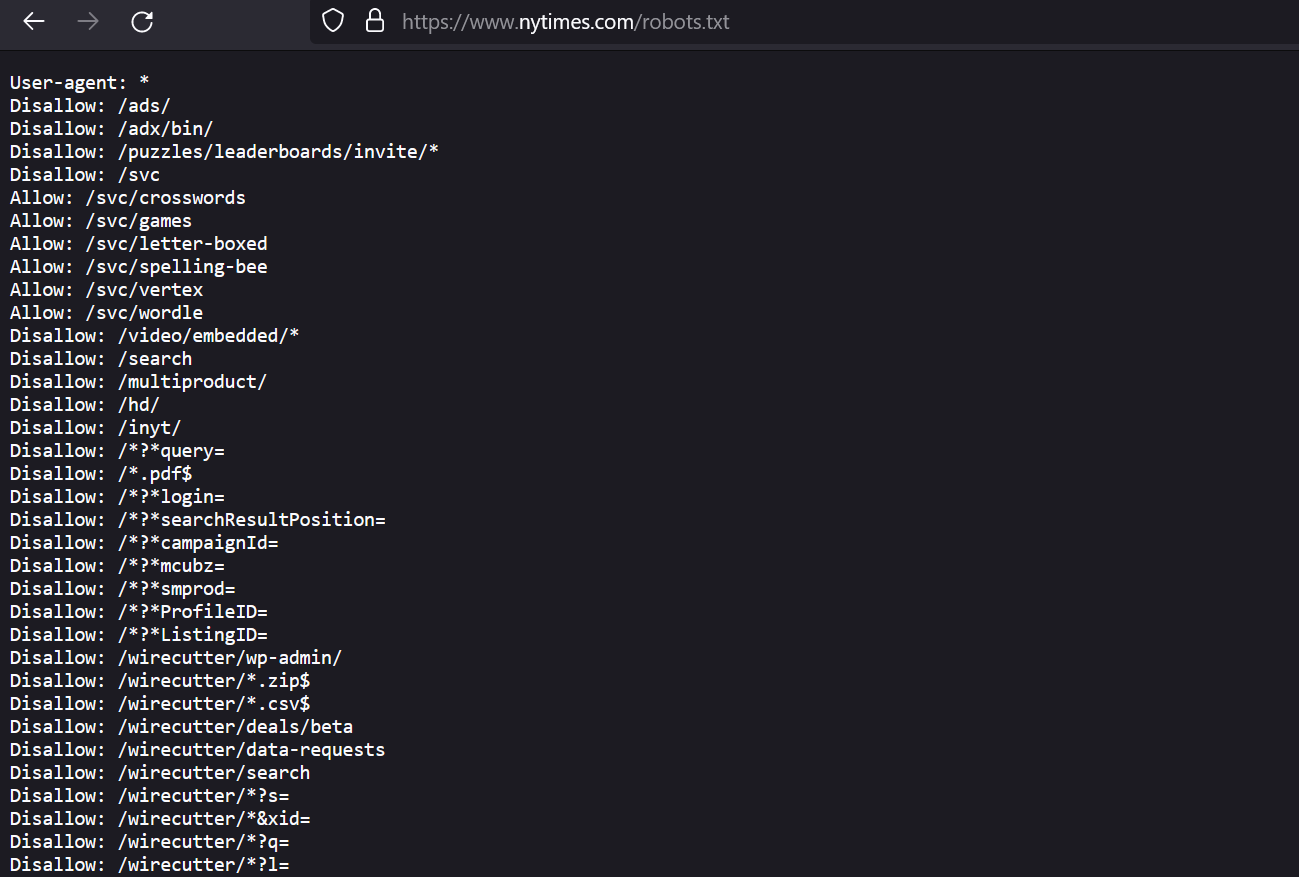
У популярних CMS SEO-плагіни часто можуть впливати на структуру robots. У цьому випадку шаблони, створені вебмайстром, не захищені від зникнення. Якщо файл перезапишеться, власник сайту може довго це не помічати.
Також потрібно переконатися, що robots доступний для роботів. Для цього слід використати спеціалізовані інструменти аналізу. У випадках, коли відповідь сервера 200, проблем із доступом не буде.
4. Синтаксис і підтримувані директиви
Новачкам у SEO створення robots може здатися важким завданням, але насправді нічого складного в роботі з файлом немає. Якщо дізнатися, які операції робить символ # або регулярні вирази, їх можна без проблем використовувати.
У robots.txt є специфічний синтаксис:
- Слеш (/) показує роботам, що саме потрібно закрити від сканування. Це може бути сторінка або великий розділ на тисячі адрес.
- Зірочка (*) допомагає узагальнити URL у правилі. Наприклад, щоб закрити від сканування всі сторінки з pdf в адресі, потрібно додати зірочку.
- Знак долара ($) прив’язується до кінцевої частини URL. Зазвичай його використовують, щоб заборонити сканування файлів чи сторінок із певним розширенням.
- Знак решітки (#) допомагає зробити навігацію файлом. За допомогою нього позначаються коментарі, які пошукові роботи ігнорують.
Новачку краще розібратися в синтаксисі одразу після того, як стане зрозуміло, що таке файл robots.txt. Навчання можна почати і з директив, але синтаксис також важливий.
Існує всього 4 основні директиви, які потрібно вивчити. Можна скласти однакові правила для всіх юзер-агентів та не витрачати зайвий час на кожного окремо. Але варто враховувати, що процес обходу сторінок у кожного спайдера відрізняється.
4.1. User-agent
У пошукових систем та онлайн-сканерів є власні юзер-агенти. За допомогою них сервер може зрозуміти, який саме робот відвідав сайт. Тоді в логах-файлах легко простежити за поведінкою певного спайдера.
User-agent використовуються в robots, щоб позначити, які саме правила застосовуються для конкретного спайдера. Коли шаблон один на всіх — у рядку використовується зірочка.
У файлі може бути хоч 50 директив із юзер-агентами, але краще зробити 3–5 окремих списків. І обов’язково додати коментарі для зручної навігації. Тоді є шанс не заплутатися у великій кількості даних.

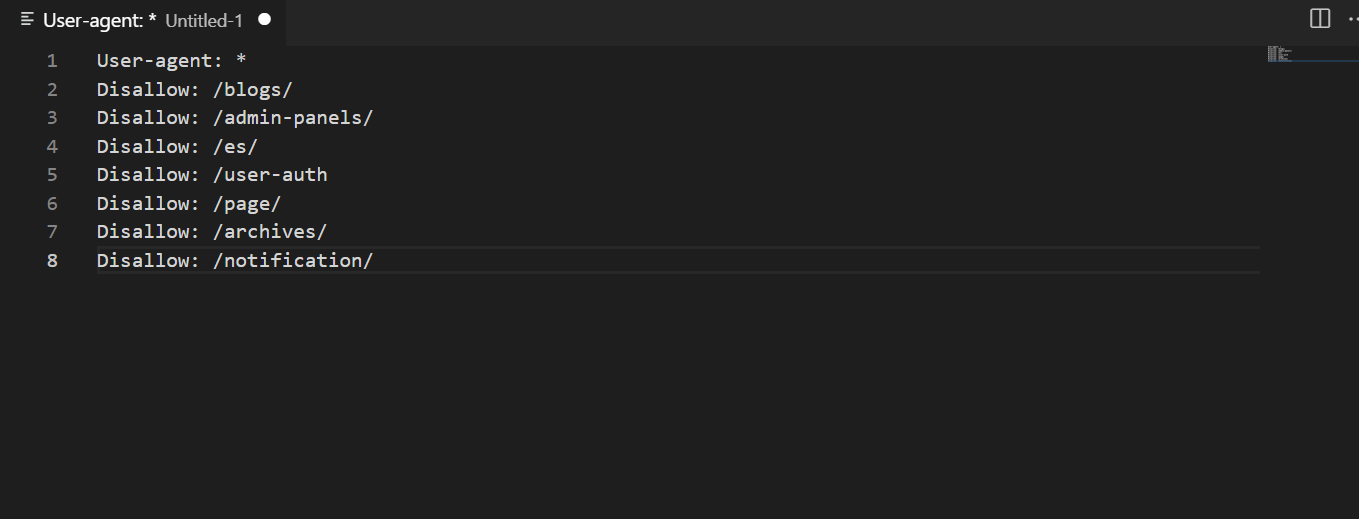
4.2. Disallow
Директива використовується, коли потрібно виключити сторінки чи розділи зі списку адрес для сканування. Вона часто застосовується для дублів, службових URL, пагінації.
Disallow обов’язково потрібно поєднувати з символом слеша. Якщо шлях до адреси не зафіксовано, пошукові павуки проігнорують правило. Тому краще впевнитися, що синтаксис правильний.
З директивою слід поводитися обережно, оскільки є ризик, що до пошукової видачі можуть не потрапити важливі адреси. Перед збереженням змін у файлі краще провести додатковий аналіз.
4.3. Allow
Однією з найкращих практик для robots.txt є використання директиви Allow. Вона дає змогу роботам сканувати сторінки або цілі розділи. Її застосовують у комбінації з Disallow, щоб створити оптимальну структуру файлу.
З Allow теж потрібно працювати уважно, щоб до пошукової видачі не потрапили службові сторінки та інші URL, які розмивають посилальну увагу всередині проєкту. Правильне використання слеша в адресах забезпечує покриття потрібних сторінок.
Коли у файлі є суперечливі правила зі сканування сторінок, для Google вирішальною є кількість символів. Виконуватиметься найдовше правило.

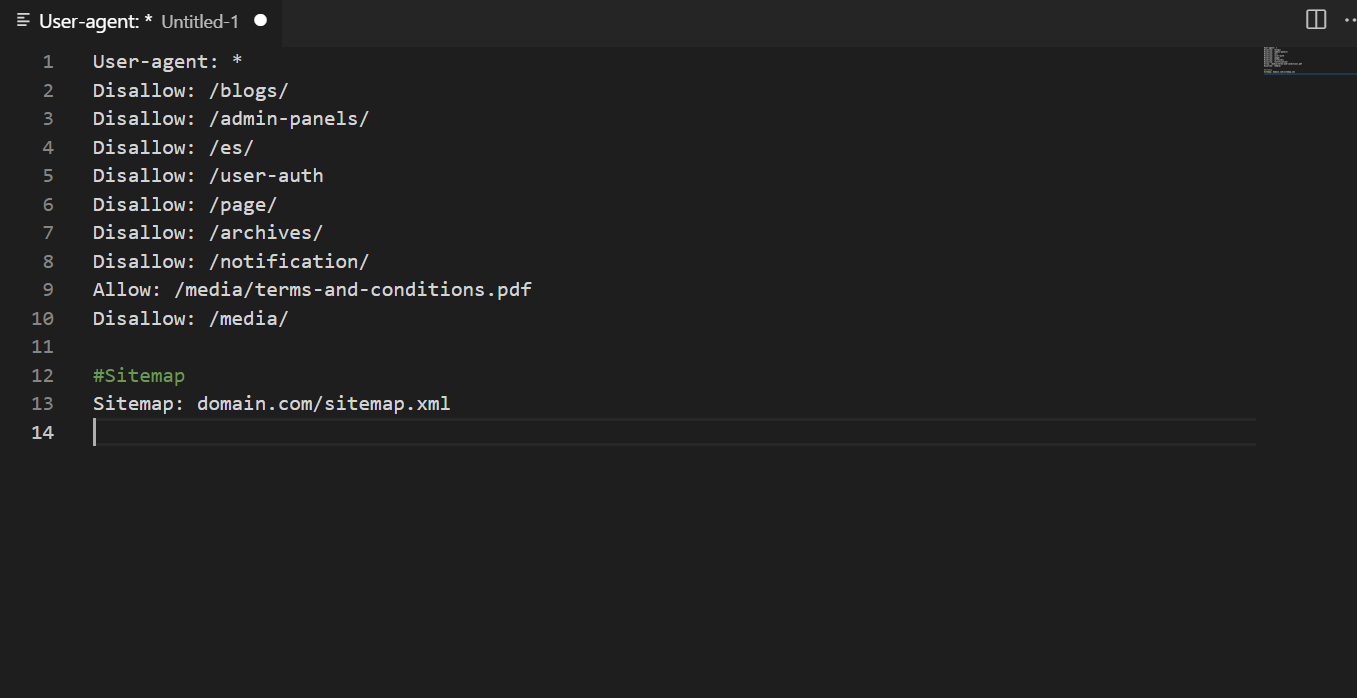
4.4. Sitemap
Директива вважається необов’язковою, але досвідчені SEO-спеціалісти рекомендують її використовувати. Вона вказує на розташування адреси з мапою сайту. Її потрібно вказувати на початку або в кінці документа.
Якщо мапу додано через Google Search Console, можна не вказувати URL ще й у robots, але шкоди від цього не буде. У 99% публічних шаблонів robots.txt sitemap обов’язково входить.
Збереження правильного синтаксису у файлі забезпечує коректне сканування вмісту роботами пошуковиків. А це позитивно впливає на технічну оптимізацію та додає балів до загального рейтингу проєкту.
5. Непідтримувані директиви Robots.txt для Googlebot
У Мережі можна побачити застарілі інструкції для robots, і новачки роблять помилки, спираючись на них. Це не завадить нормальній індексації та не зумовить проблем із ранжуванням сторінок, але краще адаптувати файл під правильний формат.
Якщо переглянути технічні файли проєктів із багаторічною історією, в них часто можна знайти застарілі директиви. Самі по собі вони не несуть шкоди, тому ігноруються пошуковими роботами. Але для ідеальної оптимізації сайту їх краще позбутися.
5.1. Crawl-delay
Раніше ця директива повністю відповідала правильному формату robots.txt. Наразі Google її не підтримує, тому немає сенсу обмежувати швидкість сканування в файлі — робот не орієнтуватиметься на ці рядки.
Bing усе ще розпізнає директиву Crawl-delay, тому можна вказати її для відповідного юзер-агента. Якщо трафіку з Бінгу немає, буде складно знайти привід для використання директиви.

5.2. Noindex
У довідковому центрі Google ніколи не було згадки про те, що можна заборонити індексацію контенту за допомогою директиви Noindex. Але деякі вебмайстри продовжують робити це в 2023 році.
У якості альтернативи можна заборонити сканування за допомогою Disallow та використати технічні інструменти для обмеження доступу на рівні сервера. Комбінація цих методів дасть змогу отримати бажаний результат.
5.3. Nofollow
Директива теж не працює, як і аналогічний тег для обмеження передачі посилальної ваги. Наразі немає ефективного способу для закриття посилань від поширення ваги.
Створення файлу robots.txt ніяк не допомагає заборонити індексацію лінків. Роботи Google легко справляються навіть із зашифрованими посиланнями, яких не видно у вихідному коді.
Серед застарілих директив також можна зустріти Host. Ця команда використовувалась для позначення головного дзеркала сайту. Вже багато років її заміною слугує 301 редирект.
6. Як створити файл Robots.txt?
Robots — це звичайний текстовий файл, який повинен лежати в корені сайту. Його можна створити за допомогою блокнота в Windows або використати стандартні інструменти файлового менеджера на сервері.
Стежте за тим, щоб файл мав правильне розширення. Інакше роботи пошукових систем не зможуть проаналізувати вміст, і у Search Console з’являтиметься сповіщення про помилку доступу.
За необхідності можна використати стандартний шаблон із відкритих джерел, але потрібно впевнитися, що в ньому немає конфліктів. Тільки після цього можна використовувати дефолтну структуру на постійній основі.

6.1. Створіть файл з ім’ям Robots.txt
Коли новачки у SEO питають, як створити файл robots.txt, відповідь лежить на поверхні. Для цього не потрібно встановлювати на комп’ютер спеціалізоване програмне забезпечення, буде достатньо «Блокнота».
Не забудьте зберегти зміни після кожного оновлення документа. В стандартній програмі немає автозбереження, тому частина даних може загубитися в процесі редагування і доведеться розпочинати роботу спочатку.
6.2. Додайте правила до файлу
Правильний шлях для оформлення правил у robots — це об’єднання юзер-агентів та використання коментарів. Немає сенсу вказувати правила для одного робота в різних частинах файлу.
Додаючи правила стежте за тим, щоб не було конфліктів. Вони призводять до того, що пошукові системи починають діяти на власний розсуд. Хоча навіть у випадку, коли все вказано правильно, немає гарантій виконання директив.
6.3. Перевірте синтаксис
Правильний robots.txt для SEO — це файл, де немає синтаксичних помилок. Найчастіше новачки допускають помилки у написанні директив. Наприклад, замість Disallow пишуть Disalow.
Ще потрібно уважно стежити за використанням слеша, зірочки та решітки. В цих символах легко заплутатися та закрити чи відкрити для сканування непотрібні сторінки. Перевірити синтаксис можна за допомогою різноманітних онлайн-сервісів.
6.4. Завантажте файл
Після створення структури файлу і збереження остаточного варіанта на комп’ютері залишається завантажити його на сервер. Для цього підходить виключно кореневий каталог.
Рекомендуємо обмежити можливість перезапису файлу, тому що після оновлення CMS та плагінів синтаксис може постраждати. Це стається не часто, але виникнення проблеми можна виключити лише таким шляхом.
6.5. Протестуйте та виправте помилки, якщо це необхідно
На створенні файлу robots.txt робота з ним не завершується. Потрібно ще впевнитися, що у ньому немає помилок. Закрити завдання можна як вручну, так і за допомогою онлайн-сканерів.
Наприклад, можна скористатися інструментом, який непогано справляється з аналізом синтаксису. У звіті відтворюється інформація про знайдені помилки та статус доступності.

Про знайдені проблеми зі скануванням та індексацією можна дізнатися в Google Search Console. Але краще не допускати їхньої появи та отримати максимальну користь від технічної оптимізації.
7. Найкращі практики роботи з Robots.txt
У роботі зі службовим файлом зазвичай немає нічого складного, але якщо йдеться про просування великих проєктів, можуть виникнути проблеми зі створенням ідеального набору правил.
Оптимізація robots.txt потребує часу і релевантного досвіду. Онлайн-сканери дають змогу заощаджувати ресурси, але не закриють абсолютно всі потреби. Тому від ручного аналізу відмовитися не вийде.
Поради з ефективної роботи з robots.txt будуть корисні вебмайстрам з будь-яким рівнем досвіду. Іноді навіть маленька помилка може зруйнувати великий обсяг виконаної роботи, і її потрібно оперативно помітити.
7.1. Використовуйте новий рядок для кожної директиви
Коли новачки починають розбиратися у синтаксисі robots.txt, вони часто припускаються однієї помилки, а саме пишуть правила в один рядок. Це становить проблему для роботів-пошуковиків.
Щоб захиститися від негативних наслідків, потрібно писати кожне правило з нового рядка. Це корисно як для спайдерів, так і для зручності навігації спеціаліста, який оновлюватиме файл.
Погано:
| User-agent:* Disallow: /admin-panel |
Добре:
| User-agent:* Disallow: /admin-panel |
7.2. Використовуйте кожного User-agent тільки раз
Коли SEO-спеціалісти-початківці цікавляться тим, що повинно бути в robots.txt, то мало хто згадує про необхідність правильного використання юзер-агентів. Знайти список популярних спайдерів не є проблемою, але це не все.
Якщо для одного робота створено 50 правил, їх варто поєднати. У пошукових роботів не буде проблем із самостійним об’єднанням, але це краще виконати ще й із погляду зручності використання файлу.
Погано:
| User-agent: Googlebot Disallow: /admins-panel …. User-agent: Googlebot Allow: /blog |
Добре:
| User-agent: Googlebot Disallow: /admins-panel Allow: /blog |
7.3 Створюйте окремі файли Robots.txt для різних субдоменів
Під час просування великих проєктів на тисячі сторінок з десятками субдоменів потрібно оптимізувати кожну директорію окремо. Справа в тому, що для пошукових систем субдомен — це новий сайт.
Robots.txt може бути шаблонним, але його потрібно помістити в кореневу директорію усіх піддоменів, які просуваються в пошуку. Це правило не стосується технічних субдоменів, закритих від користувачів.
7.4. Будьте конкретні, щоб мінімізувати можливі помилки
Дуже часто у власників інтернет-проєктів виникають проблеми із закриттям доступу до сторінок та розділів. Зазвичай це пов’язано з неправильним використанням слеша та інших знаків підстановки.
Практично кожен вебмайстер знає, що таке robots txt, але коли справа доходить до створення правил, багато хто припускається критичних помилок. І це може вплинути на індексацію та ранжування.
Наприклад, потрібно обмежити доступ до сторінок з префіксом /es, тому що директорія перебуває у розробці. В цьому випадку на результат впливає правильне використання слеша.
Погано:
| User-agent: * Disallow: /es |
Добре:
| User-agent: * Disallow: /es/ |
У другому випадку під обмеженням перебувають усі сторінки, які належать до відповідної директорії. А в першому випадку можуть виникнути проблеми з усіма адресами, де є конструкція es.
7.5. Використовуйте коментарі, щоб пояснити свій файл Robots.txt людям
Павуки пошукових систем ігнорують будь-які рядки, де використовується символ решітки. А вебмайстрам коментарі дають змогу орієнтуватися в структурі документа. Тому їх однозначно слід використовувати і приділити увагу під час вивчення, що таке robots.txt в SEO.
Відсутність коментарів не можна назвати поганою практикою, коли в документі 10–20 рядків. А ось якщо їх сотні, краще написати підказки для себе та SEO-спеціалістів, які працюватимуть над проєктом у майбутньому.
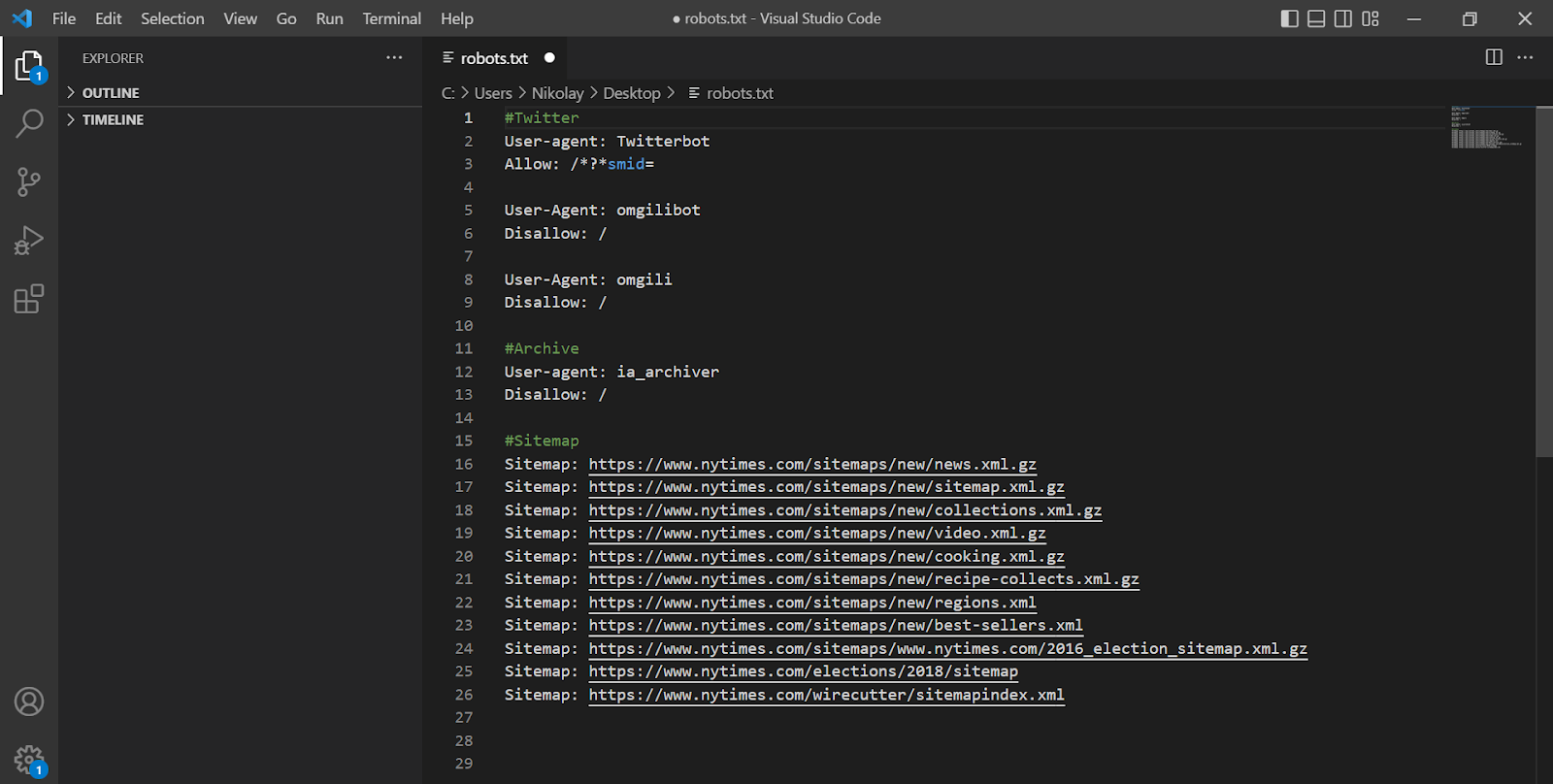
Лайфхаки з оптимізації robots також можна підгледіти на авторитетних проєктах, які не мають проблем із пошуковим трафіком. Більшість із них є у каталогу PRPosting. Для аналізу достатньо зібрати список із 5–10 ресурсів і подивитися на їхні версії файлу.
Також в особистому кабінеті сервісу можна поспілкуватися з оптимізаторами під час угоди з розміщення посилань. Так можна гармонійно поєднати внутрішню і зовнішню оптимізацію.

8. Висновки
Багато хто знає, як знайти robots.txt, але не всі вміють правильно працювати з файлом. Для засвоєння базових принципів оптимізації файлу не потрібно багато часу, тому варто його витратити та постійно вдосконалювати знання.
Що таке файл Robots.txt?
Це технічний файл, який містить правила зі сканування сторінок сайту. Пошукові роботи використовують його, щоб зрозуміти, які розділи не є пріоритетними для індексації.
Як створити файл Robots.txt?
Це можна зробити за допомогою «Блокнота», FTP-менеджера або використати спеціалізовані сервіси. В кожному випадку результат буде однаковим.
Як знайти Robots.txt?
На відміну від мапи сайту, файл повинен бути в кореневій директорії. Якщо він лежить в іншому місці, сенсу буде нуль.
Який максимальний розмір файлу Robots.txt?
Приблизне обмеження — 500 КБ. Вага залежить від кількості рядків, цю межу складно перейти, якщо вживаються заходи з оптимізації.







