
Przewodnik po Duplicate Content w SEO

Czym jest Duplicate Content?
Zduplikowana treść pojawia się na wielu stronach internetowych. Zwykle problem pojawia się, gdy ta sama treść jest publikowana na różnych stronach internetowych z różnymi domenami. Czasami jednak rozmieszczenie tej samej treści na kilku stronach tego samego zasobu również zmniejsza skuteczność optymalizacji pod kątem wyszukiwarek.
Zduplikowany tekst, wypełniony słowami kluczowymi, ma największy wpływ. Można jednak również znaleźć się w trudnej sytuacji z powodu masowego udostępniania obrazów i filmów.
Używamy tych samych słów, autorzy wpadają na podobne pomysły, a nawet oryginalne filmy mogą zawierać materiały z innych filmów. Ponadto różne strony witryny często zawierają dane kontaktowe i warunki prawne świadczenia usług, których nie można zmienić. Zawsze mamy więc do czynienia z pewnym odsetkiem duplikatów.
Ile absolutnie unikalnej treści powinna zawierać strona internetowa? Same wyszukiwarki nie dają konkretnej odpowiedzi, a eksperci podają różne liczby. Jedną z najbardziej realistycznych liczb podaje Tony Wright, który regularnie publikuje swoje badania w Search Engine Journal. Twierdzi on, że strona internetowa powinna zawierać co najmniej 30% treści, których nie można znaleźć gdzie indziej. Dotyczy to zarówno innych stron zasobu, jak i innych domen.

Czy to takie proste? Nie do końca. Przypomnijmy, że niektóre szczegóły są powtarzane w strukturze witryny — podtytuły, kontakty, menu nawigacyjne. Stanowią one do 20% całkowitej zawartości strony. Większość zasobów cytuje również z innych stron — nawet sklepy internetowe mogą pobierać informacje reklamowe od producentów. Pewien procent tekstu jest zapożyczany zupełnie przypadkowo — po prostu dlatego, że autorzy korzystają z tego samego źródła informacji. Co więcej, liczba ta z czasem rośnie, ponieważ w danym segmencie stale pojawiają się nowi konkurenci.
Dlatego nawet przy starannym podejściu do zarządzania treścią udział duplikatów waha się od 25 do 50%. Oznacza to, że musisz stale monitorować jakość treści swojej witryny — zlecać copywriting i rozwój elementów multimedialnych, okresowo aktualizować strony i dodawać nowe materiały. Nie można zatrzymać się w tym procesie, w przeciwnym razie istnieje ryzyko utraty kontroli nad sytuacją.
Dlaczego zduplikowana treść ma tak duże znaczenie?
Wyobraź sobie, że przychodzisz do supermarketu i widzisz dwa identyczne produkty od różnych producentów, które mają prawie identyczną cenę. Który z nich jest lepszy? Który byś kupił? Taki wybór prowadzi większość ludzi do ślepego zaułka — najczęściej odrzucają oba produkty i znajdują alternatywę. Dokładnie to samo robią wyszukiwarki, gdy widzą zduplikowane treści.
Jeśli strony w dwóch zasobach kopiują się nawzajem, robot nie będzie szukał oryginału. Po prostu podzieli między nie punkty przyznane za autorytet, link building i wartość akademicką. W rezultacie wszystkie duplikaty otrzymają niższy ranking i zostaną obniżone na stronie wyników wyszukiwania. Jeśli sytuację pogorszą inne naruszenia, sprawa może skończyć się nawet odmową indeksacji, choć w praktyce taka decyzja jest rzadko podejmowana.
Oczywiście Google, Bing i ich konkurenci biorą pod uwagę nie tylko treść na stronie. Może to jednak prowadzić do paradoksalnej sytuacji, w której zapożyczone materiały uzyskują wyższą pozycję w rankingu. Dzieje się tak, gdy konkurenci mają lepszą optymalizację techniczną. Dlatego monitorowanie Internetu pod kątem kopii jest niezbędną koniecznością dla właściciela dowolnego zasobu.
Jak zduplikowane treści wpływają na SEO?
Obniżenie pozycji w wynikach wyszukiwania — to efekt długoterminowy, który można uzyskać w przypadku ignorowania problemu przez dłuższy czas. Jednak problemy ze zduplikowaną treścią mogą zacząć się natychmiastowo. Porozmawiajmy o nich bardziej szczegółowo.
Marnowanie budżetu przeznaczonego na crawling
Termin ten odnosi się do czasu, jaki Google przeznacza na indeksowanie witryny. Jeśli zawiera ona wiele stron, w tym zduplikowane treści, najbardziej wartościowe sekcje mogą nigdy nie zostać zaindeksowane przez wyszukiwarkę. Aby rozwiązać ten problem, należy ręcznie wyłączyć indeksowanie duplikatów i poczekać na kolejne przetworzenie zasobu. W tym czasie możesz stracić swoje rankingi, odwiedzających i zyski.
Mniejsza liczba zaindeksowanych stron
Zdarza się to bardzo rzadko, ale czasami karą za zduplikowane treści jest wykluczenie strony z wyszukiwarki. Konsekwencje są oczywiste: dla odnoszącej sukcesy firmy jest to ogromna strata. Problem można rozwiązać poprzez aktualizację treści lub odwołanie się od decyzji. Jednak w każdym przypadku będziesz musiał poświęcić na to dużo czasu i poczekać na kolejne indeksowanie.
Rozdzielenie masy referencyjnej
Jeśli wyszukiwarka widzi kilka identycznych stron i nie może zidentyfikować oryginału, dzieli punkty rankingowe między wszystkich konkurentów. Oznacza to, że system linków zewnętrznych, który budowałeś przez kilka miesięcy, będzie korzystny nie tylko dla Ciebie, ale także dla Twojej konkurencji. Jest to bardzo nieprzyjemna perspektywa — można ją porównać do szpiegostwa przemysłowego, w którym inne firmy otrzymują Twoje tajemnice handlowe za darmo.

Spadek ruchu organicznego
Ostateczny wynik, który wynika z poprzednich punktów. Im dłużej ignorujesz problem zduplikowanych treści, tym niższe stają się Twoje rankingi w wyszukiwarkach i tym mniej odwiedzających samodzielnie znajduje Twoją witrynę. Dlatego ważne jest, aby jak najszybciej zidentyfikować i naprawić błędy w strategii SEO.
Główne przyczyny powielania treści
Wydaje się to oczywiste. Ktoś stworzył zduplikowaną stronę internetową, mając nadzieję na wykorzystanie popularności konkurenta i osiągnięcie natychmiastowego zysku. Jednak w praktyce sprawy nie są takie proste. Istnieją również czysto techniczne powody, które przez długi czas mogą nie być oczywiste dla specjalisty SEO.
Automatyczne lub ręczne kopiowanie treści
W przypadku osobistego bloga dość łatwo jest kontrolować jego zawartość. Zasoby komercyjne są znacznie bardziej skomplikowane. Na przykład sklepy internetowe często automatycznie parsują funkcje ze stron producentów. A agencja marketingowa może kopiować oferty od swoich kontrahentów lub partnerów biznesowych w niezmienionej formie. Jest to najczęstszy powód duplikowania treści.
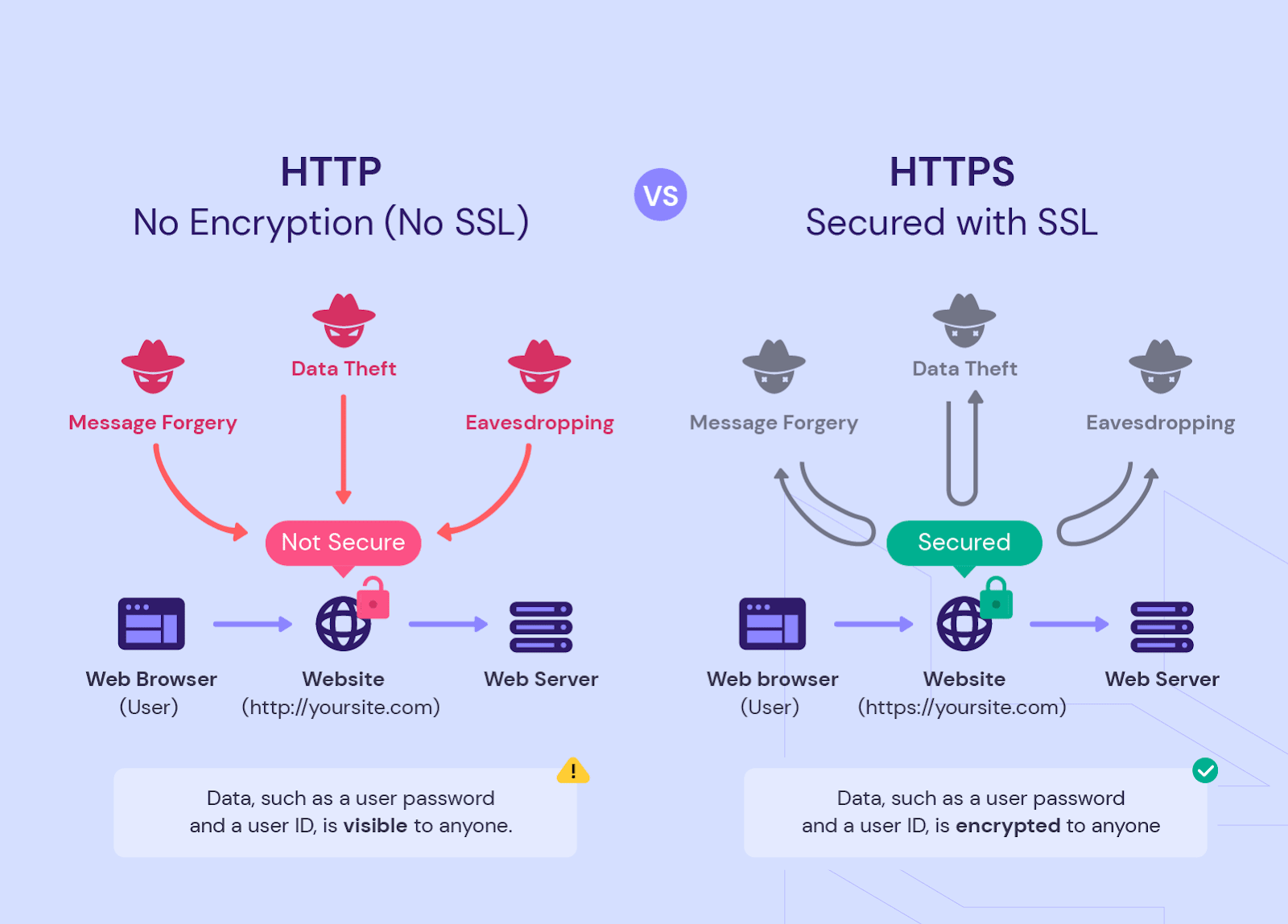
Różnica między HTTP i HTTPS, adresami z prefiksem WWW i bez niego
Dobrze jest posiadać stronę internetową, która działa z bezpiecznym protokołem HTTPS i nie posiada prefiksu WWW. Dotyczy to jednak tylko nowych zasobów. Starsze witryny, oprócz głównej, często mają wersje HTTP i WWW. Jeśli całkowicie powielają one treść i są indeksowane przez wyszukiwarki, może to zmniejszyć skuteczność strategii SEO.
Syndykacja treści
Niektóre strony koncentrują się wyłącznie na repostach. Zbierają wszystkie interesujące materiały na dany temat w jednym miejscu, zyskując uwagę odbiorców. Jednocześnie autorzy budują sieć linków i wzmacniają swoje pozycje w optymalizacji pod kątem wyszukiwarek. Ślepe powielanie stron może jednak prowadzić do kar ze strony Google. Dlatego syndykację treści należy powierzać wyłącznie zaufanym partnerom.
Wariacje adresów URL
Na dużych stronach internetowych użytkownicy mogą uzyskać dostęp do tej samej strony pod różnymi adresami. Na przykład mogą uzyskać do niej dostęp z zasobów zewnętrznych, korzystając z filtrów w katalogu sklepu internetowego lub podążając za linkiem polecającym. Taka sytuacja ma zwykle miejsce w przypadku korzystania ze standardowego systemu zarządzania treścią. Upraszcza to nawigację, ale stwarza dodatkowe ryzyko.
Porządkowanie parametrów
Ten problem wynika z poprzedniego. Niektóre systemy CMS nie ustalają sposobu wyboru strony w katalogu lub menu nawigacyjnym. W rezultacie można uzyskać tę samą treść za pomocą filtrów /?size=500&colour=3 i /?color=&3size=500. Wyszukiwarka spróbuje zaindeksować oba warianty i wykryć zduplikowaną treść.
Grupowanie komentarzy
Popularne artykuły i karty produktów otrzymują setki, jeśli nie tysiące, reakcji. Wyświetlanie ich na jednej stronie jest złym pomysłem z punktu widzenia optymalizacji technicznej. Witryna będzie działać znacznie wolniej. Większość CMS-ów posiada funkcję paginacji, czyli dzielenia komentarzy na kilka stron. Standardowo tworzy ona jednak kilka wersji adresu URL, które różnią się jedynie recenzjami.

Linki do wersji mobilnych i stron AMP
Duplicate content w Google często pojawia się podczas optymalizacji witryny pod kątem smartfonów i tabletów. Tworzone są dla nich alternatywne strony, które są również uwzględniane w indeksie. Zawartość tych stron jest prawie identyczna z wersjami desktopowymi.
Linki do obrazów
Domyślnie WordPress i inne popularne systemy CMS tworzą osobną stronę dla przesłanego obrazu. Nie ma to prawie żadnej wartości SEO, ale stwarza ryzyko duplikowania treści i obniżenia rankingu witryny. Aby uniknąć takiej sytuacji, lepiej umieścić link do oryginalnej lokalizacji obrazu.
Tagi i kategorie
Pojęcia te są często używane do wyszukiwania na blogach, w sklepach internetowych i innych zasobach. Należy jednak być bardzo odpowiedzialnym podczas tworzenia struktury witryny. Tagi i kategorie, które są zbyt zbliżone znaczeniowo, mogą zostać rozpoznane jako zduplikowane strony. To samo dotyczy sortowania. Jeśli w tagu lub kategorii będzie znajdował się nawet jeden element, strona tego artykułu lub karty produktu zostanie zduplikowana.
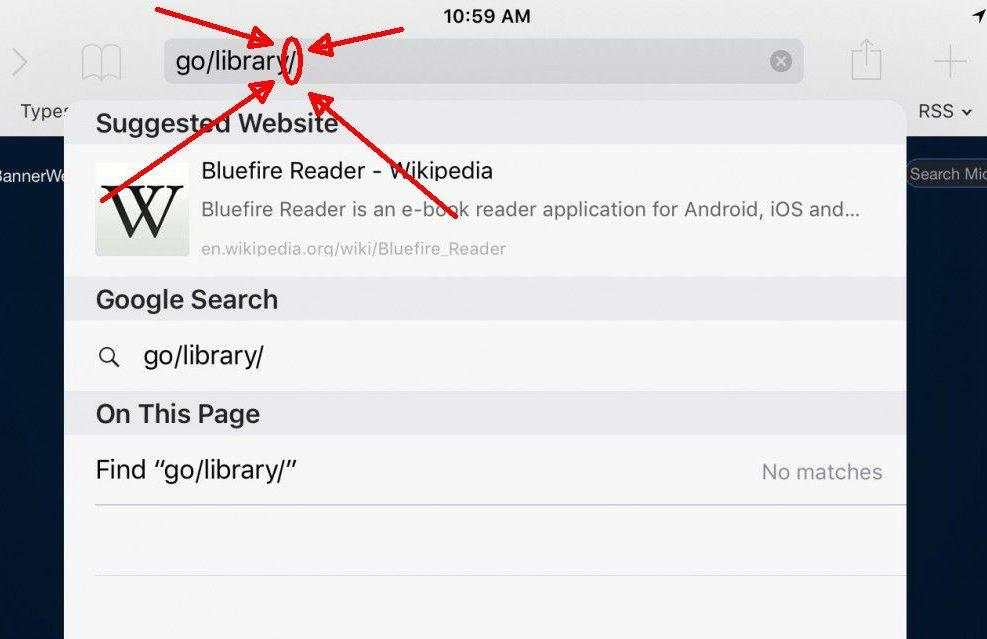
Adresy URL zoptymalizowane dla druku
Zazwyczaj ten rodzaj duplicate content w SEO pojawia się w katalogach online, bibliotekach i witrynach kancelarii prawnych. Starając się poprawić UX, od razu przygotowują dokumenty do druku. Skutkuje to jednak zduplikowaną stroną, która różni się tylko formatem, a nie treścią.
Adresy URL uwzględniające wielkość liter
Nieprzyjemny problem, który trudno zdiagnozować. Sekret tkwi w tym, że Google rozróżnia wielkie i małe litery w linkach. Jeśli Twoja witryna daje tę samą odpowiedź na zapytania z różnymi wielkościami liter, wyszukiwarka uzna ją za dwie zduplikowane strony.
Identyfikatory sesji
Najczęściej są używane przez sklepy internetowe. Tymczasowo przechowują historię działań użytkownika, takie jak wypełnianie koszyka lub przeglądanie produktów. Zazwyczaj system ten wykorzystuje pliki cookie. Jednak niektóre systemy CMS domyślnie tworzą nowe adresy URL, całkowicie duplikując zawartość nieograniczoną liczbę razy.
Opcje śledzenia
Zawsze ważne jest, aby wiedzieć, skąd przychodzi odwiedzający. Pomoże to zbudować odpowiedni lejek sprzedażowy i stworzyć najlepszą ofertę handlową. Jednak dodawanie parametrów śledzenia do adresu URL prowadzi do tworzenia niechcianych linków do tych samych stron, które mogą być indeksowane przez wyszukiwarki.
Myślniki na końcu adresu URL
Historycznie, link kończący się na “/” zapewniał dostęp do folderu, a nie konkretnej strony internetowej. Obecnie nie ma to już znaczenia. Wyszukiwarki uznają jednak linki z myślnikami końcowymi i bez nich za różne strony.
Strona index
Jest niezbędna do prawidłowego funkcjonowania strony internetowej i prawidłowego przetwarzania linków przez wyszukiwarki. Jednak nie zawsze jest ona wyświetlana jako główny adres URL. Prowadzi to do powielania stron i klonowania treści w ramach jednego zasobu.
Indeksowanie środowiska programistycznego i testowego
Prace nad aktualizacją witryny i dodawaniem funkcji są często przeprowadzane “na żywo”. Umieszczając strony testowe na serwerze, można od razu przetestować je w rzeczywistych warunkach. Nie należy jednak zapominać o usunięciu poprzednich wersji lub wykluczeniu ich z indeksowania w wyszukiwarkach. Z powodu zwykłej nieuwagi nowe strony mogą pozostać bez ruchu organicznego.
Jak znaleźć na stronie duplicate content?
Ręczne wyszukiwanie nie jest dobrym pomysłem. Nawet jeśli wiesz, czym jest zduplikowana treść i co ją powoduje, zawsze możesz przeoczyć drobne kwestie techniczne. A gdy liczba stron w witrynie jest mierzona w setkach, zadanie przechodzi do kategorii Mission Impossible.
Najlepszą opcją jest skorzystanie z narzędzi do kompleksowego audytu SEO. Poniższe narzędzia oferują własne aplikacje:
- MOZ;
- SEMRush;
- SERPStat;
- Sitechecker;
- Ahrefs.
Warto zauważyć, że są to płatne zestawy narzędzi. Podstawowa subskrypcja kosztuje od 50$ do 100$ miesięcznie. Oferują one jednak wiele przydatnych funkcji, w tym badanie słów kluczowych, budowanie linków i audyt techniczny.
Możesz także skorzystać z darmowych narzędzi do sprawdzania unikalności, aby znaleźć podobne treści w Internecie. Są to na przykład Copywritely, Copyscape i Grammarly. W wersji podstawowej oferują one ograniczoną liczbę wyszukiwań. Aby zwiększyć ilość zapytań i aktywować funkcję ciągłego monitorowania, należy wykupić płatną subskrypcję.
Najczęstsze sposoby rozwiązywania problemów ze zduplikowaną treścią
Oczywiście każdy przypadek należy rozpatrywać indywidualnie. Czasami dwa problemy, które wyglądają podobnie, mogą różnić się szczegółami technicznymi. Poniżej znajduje się jednak lista rozwiązań, które pomogą pozbyć się 80% nieumyślnie zduplikowanych treści.
301 Redirect
Łatwiejsze niż restrukturyzacja, skuteczniejsze niż inne metody. Jeśli masz zduplikowane treści w swojej witrynie, ponieważ masz wersje HTTP i HTTPS, a także strony z prefiksem WWW i bez niego, przekieruj ruch na właściwą stronę. Gdy roboty indeksujące zobaczą ten kod, podążą za linkiem i zaindeksują tylko te treści, które dla nich określisz.

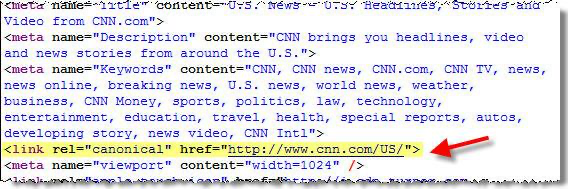
Rel=”canonical”
Wskazuje na stronę, która zawiera oryginalną treść. Nakazuje robotom wyszukiwarek ignorować wszystkie kopie strony, w tym tych zoptymalizowanych pod kątem druku i urządzeń mobilnych, utworzonych podczas opracowywania i testowania. Przedstawiciele Google wielokrotnie podkreślali, że przekierowania 301 i tag strony kanonicznej są najskuteczniejszymi sposobami kontrolowania indeksowania.
Meta robots noindex
Gdy wyszukiwarka zobaczy ten tag, zignoruje stronę. Pamiętaj jednak, że nadal może podążać za linkami na niej, jeśli nie zablokowałeś tej funkcji. Metoda ta pozwala zablokować kilka niechcianych stron w witrynie. Nie należy jednak dać się jej zbytnio ponieść. Inżynierowie Google twierdzą, że zwiększa to czas odpowiedzi zasobu i czas trwania crawlingu.

Konfiguracja domeny w Google Search Console
Zaloguj się do tego serwisu, wybierz potrzebny projekt i przejdź do ustawień witryny. Wybierz domenę, która ma być indeksowana. Można na przykład zignorować wersje HTTP lub WWW stron. Wcześniej można było określić indywidualne ustawienia indeksowania dla każdego adresu URL w aplikacji, ale ta funkcja zniknęła w 2022 roku. Wadą tej metody jest to, że wydaje ona polecenie tylko robotowi wyszukiwarki Google. Wszystkie inne systemy będą nadal indeksować strony ze zduplikowaną treścią.

Konsolidacja treści
Na przykład opublikowałeś kilka postów o podobnej, ale nie identycznej treści. Ze względu na niską unikalność, mogą one nie być dobrze pozycjonowane w wynikach wyszukiwania. Aby rozwiązać ten problem, wystarczy połączyć wszystkie strony w jedną. Napisz jeden tekst, dodając unikalne tezy z każdego artykułu. Całą resztę można wyróżnić lub zablokować dla robotów wyszukiwarek. Rezultatem będzie znaczny wzrost w SERP.

Duplicate content — jak bardzo jest szkodliwy?
W każdym razie żadna strona nie może być w 100% unikalna. Dlatego wyszukiwarki są dość lojalne wobec obecności tej samej treści w różnych sekcjach witryny. Do pewnego momentu. Jeśli zasób zawiera kilka stron, które powtarzają się w 100% lub pożyczyłeś treści od konkurencji, zaczynają się problemy. Na początku jest to spadek w rankingach i spadek ruchu organicznego. Ignorując ostrzeżenia i kontynuując tak ryzykowną politykę, można całkowicie wypaść z indeksowania w wyszukiwarce.
Dlatego należy jak najszybciej naprawić problem. Aby znaleźć go na czas, skorzystaj z uniwersalnych serwisów audytu SEO lub specjalistycznych narzędzi. W większości przypadków rozwiązaniem będą powszechne metody radzenia sobie z duplikatami treści — przekierowania, tagi i polecenia dla robotów wyszukiwarek. Jeśli to nie pomoże, należy zmienić treść, zlecając copywriting i opracowanie elementów multimedialnych.
Często zadawane pytania
Czym jest duplicate content?
Treść tekstowa lub multimedialna, która pojawia się na innych stronach tej samej witryny lub w innych domenach w Internecie.
Jak szkodliwe są zduplikowane treści?
Eksperci twierdzą, że 30-60% unikalnej treści można uznać za normę, w zależności od konkretnych warunków. Tylko duże fragmenty tekstów lub znaczne ilości obrazów zapożyczonych z innego źródła będą szkodliwe.
Czy Google karze za nieunikalne treści?
Wyszukiwarka nie stawia bezpośrednich ograniczeń. Jeśli jednak pojawia się kilka kopii tej samej strony, automatycznie dzieli między nie punkty rankingowe, obniżając ich pozycje. Odmowa indeksowania jest stosowana bardzo rzadko — zazwyczaj dzieje się tak tylko w przypadku licznych naruszeń regulaminu.
Jakie są najpopularniejsze sposoby radzenia sobie z duplicate content?
Można identyfikować oryginalną stronę za pomocą tagu Rel=”canonical”, ustawiać automatyczne przekierowania, blokować indeksowanie nieunikalnych treści, konsolidować treści lub wybierać właściwą domenę w Google Search Console.





Więcej podobnych
Czym jest link polecający i jak on działa?

