
Что такое файл Robots.txt и как им правильно пользоваться

Обычно сразу после запуска сайта веб-мастера создают карту, закрывают от индексации служебные страницы и добавляют метатеги. Но иногда они забывают о важных задачах, которые лучше закрыть в первую очередь.
Даже новички знают, что такое robots.txt, но не все владельцы сайтов уделяют внимание работе с ним. В некоторых случаях файл генерируют с помощью SEO-плагинов и забывают о его существовании. Это может привести к проблемам с индексацией и ранжированием в будущем, поэтому лучше следить за состоянием файла.
1. Что такое файл Robots.txt?
Robots.txt — это служебный документ, содержащий правила для поисковых роботов. Сканеры поисковиков учитывают его, когда им нужно обойти страницы и принять решение об индексации URL.
Файл следует расценивать как инструмент снижения нагрузки на сервер проекта, а не как способ быстрой блокировки доступа к служебным страницам. Он работает аналогично тегу nofollow для ссылок — поисковые роботы могут учитывать правила, но гарантии нет.
Обычно поисковики выполняют имеющиеся директивы, но в каждом случае решение принимается на основе совокупности факторов. К примеру, когда в файле есть противоречивые строки, активируются дополнительные алгоритмы анализа.
Качественно скомпонованный robots.txt может принести пользу в SERP, но он — лишь один кирпич из тысяч необходимых для хорошего ранжирования. Поэтому не стоит слишком зацикливаться на постоянном обновлении файла.
1.1. Как он работает?
Чтобы разобраться, как работает robots, нужно углубиться в технические нюансы. На это не потребуется много времени — базовые знания можно получить за несколько часов из справочного раздела Google для веб-мастеров.
Роботы поисковиков выполняют две главные операции — сканируют содержимое страниц и индексируют их. Robots.txt — это нечто вроде указателя. Он указывает спайдерам маршрут, по которому можно сканировать ресурс. А вот учитывают ли роботы подсказки, заранее узнать невозможно.
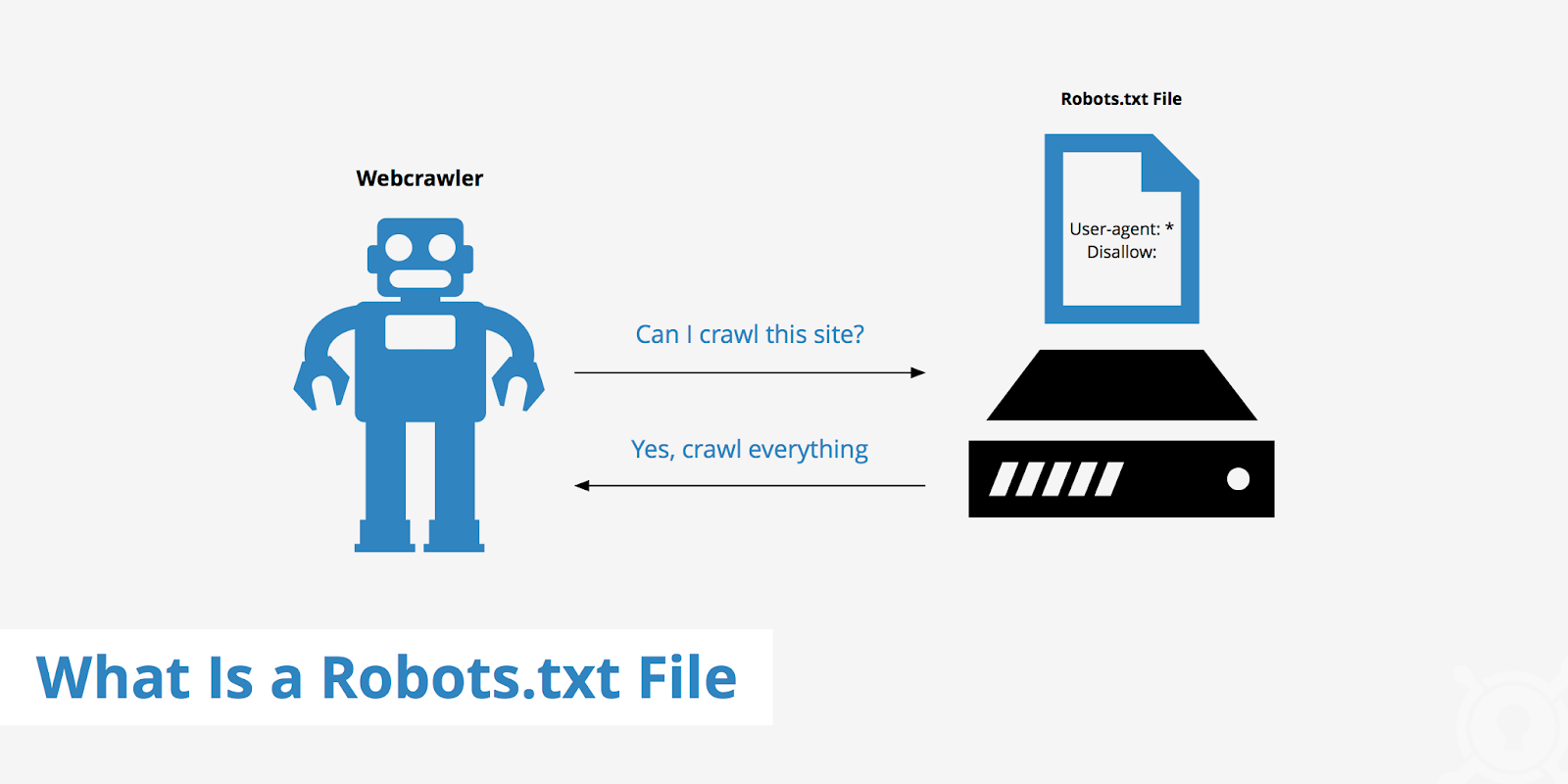
Обычно перед сканированием ресурсов поисковые пауки анализируют содержимое файла robots.txt, чтобы понять, какие страницы владелец проекта не хочет добавлять в индекс. Они могут прислушиваться к подсказкам или нет.
Robots часто расценивают как эффективный инструмент для запрета индексации, но это не так. Если алгоритмам поисковика покажется, что на странице есть полезный для пользователей контент, она может попасть в индекс.
Также необходимо понимать, что сканеры разных сервисов работают с синтаксисом технического файла по уникальному сценарию. Поэтому, если не создать собственные правила для конкретного пользователя-агента, в выдачу могут попасть лишние адреса.
Чтобы на 100% защититься от добавления страницы в выдачу, нужно закрыть к ней доступ с помощью .htaccess или других серверных инструментов. Тогда URL не нужно будет указывать в robots txt для Google.
2. Зачем нужен Robots.txt?
Есть мнение, что в 2023 году создавать файл robots нет нужды. На самом деле это ошибочное утверждение, потому что этот файл используется поисковыми спайдерами. А это стимул для того, чтобы потратить время на создание документа.
Robots.txt не является панацеей для запрета индексации страниц, но он обычно умело показывает поисковикам адреса, которые не следует обходить. Это экономит время спайдеров и ресурсы сервера.
Также, если документа нет в корневой директории, поступит уведомление в Google Search Console. Ничего критичного в проблеме нет, но лучше не давать алгоритмам лишнего повода для повышенного внимания к проекту.
Не нужно создавать служебный файл для продвигаемых ресурсов за пределами поисковых систем. Это относится к SaaS и другим сервисам с постоянной аудиторией. Решение о необходимости выполнения SEO-задач каждый веб-мастер принимает самостоятельно, но дополнительные переходы не будут лишними в любом случае.
2.1. Оптимизация краулингового бюджета
Краулинговый бюджет — это лимит на сканирование страниц ресурса. Роботы Google по-разному сканируют адреса каждого проекта, поэтому заранее не удастся понять, как быстро они обойдут все URL.
Оптимизация бюджета на сканирование страниц подразумевает закрытие служебных разделов в robots.txt для Googlebot. Если это сделать, пауки поисковика не будут тратить ресурсы на обход лишних адресов, и индексация важных URL может ускориться.
Краулинговый бюджет — очень непредсказуемая вещь, но оптимизация robots может положительно повлиять на скорость обхода страниц спайдерами. Поэтому не следует игнорировать эту задачу.
2.2. Блокировка дубликатов и непубличных страниц
Дубли провоцируют размывание ссылочного веса и ухудшают ранжирование страниц. Например, если на сайте 50 дубликатов URL, получающих переходы из поисковиков, лучше от них избавиться.
Также на каждом сайте есть страницы, которые не должны попадаться на глаза пользователям: административная панель, адрес с приватной статистикой и т.д. Доступ к ним лучше заблокировать на уровне сервера и дополнительно указать в robots.

2.3. Предотвращение индексации ресурсов
Кроме страниц, можно использовать директивы в служебном файле для отказа от сканирования медиаконтента. Это могут быть изображения, файлы PDF, Word-документы и другое содержимое.
Блокировки в robots обычно достаточно, чтобы файлы с медиаконтентом не появились в поисковой выдаче. Но в некоторых случаях могут возникать проблемы. Если алгоритмы Google или других сервисов примут другое решение, то его можно обойти только с помощью полного запрета на уровне сервера.
На ограничение доступа изображений или скриптов в служебном файле требуется минимум времени. Надо найти robots.txt и использовать специальные символы подстановки, чтобы под созданные правила попали все документы.
Качественный robots без ошибок — это бонус в копилку проекта. Если конкуренты имеют проблемы с технической оптимизацией, это может стать одной из возможностей обойти их в борьбе за трафик.
3. Как найти Robots.txt?
Найти служебный файл можно через несколько секунд в корневой директории сайта по адресу domain.com/robots.txt. Если речь идет о субдомене, необходимо изменить только первую часть адреса.
Иногда возникают проблемы с перезаписью файла, поэтому лучше запретить операцию через FTP-менеджер. Если вручную отключить возможность конфигурации содержимого, robots.txt для SEO будет работать на полную мощность.

В популярных CMS SEO-плагины часто могут оказывать влияние на структуру robots. В этом случае шаблоны, созданные веб-мастером, не защищены от исчезновения. Если файл перезапишется, владелец сайта может этого долго не замечать.
Также нужно убедиться, что robots доступен для роботов. Для этого следует использовать специализированные инструменты анализа. Если ответ сервера 200, проблем с доступом не будет.
4. Синтаксис и поддерживаемые директивы
Новичкам в SEO создание robots может показаться трудной задачей, но на самом деле ничего сложного в работе с файлом нет. Если узнать, какие операции делает символ # или регулярные выражения, их можно использовать без проблем.
В robots.txt есть специфический синтаксис:
- Слеш (/) показывает роботам, что именно нужно закрыть от сканирования. Это может быть страница или большой раздел на тысячи адресов.
- Звездочка (*) помогает обобщить URL в правиле. Например, чтобы закрыть от сканирования все страницы из PDF в адресе, нужно добавить звездочку.
- Знак доллара ($) привязывается к конечной части URL. Обычно его используют для запрета сканирования файлов или страниц с определенным расширением.
- Знак решетки (#) помогает сделать навигацию по файлу. С помощью него обозначаются комментарии, которые игнорируют поисковые работы.
Новичку лучше разобраться в синтаксисе сразу после того, как станет понятно, что такое файл robots.txt. Обучение можно начать и с директив, но синтаксис также важен.
Существует всего 4 основных директивы, которые нужно выучить. Можно составить одинаковые правила для всех пользователей-агентов и не тратить лишнее время на каждого отдельно. Но следует учитывать, что процесс обхода страниц у каждого спайдера отличается.
4.1. User-agent
У поисковых систем и онлайн-сканеров есть собственные пользовательские агенты. Посредством них сервер может понять, какой именно робот посетил сайт. Тогда в логах-файлах просто проследить за поведением определенного спайдера.
User-agent используются в robots, чтобы обозначить, какие правила применяются для конкретного спайдера. Когда шаблон один на всех, в строке используется звездочка.
В файле может быть хоть 50 директив с пользователями, но лучше сделать 3–5 отдельных списков. И обязательно добавить комментарии для удобной навигации. Тогда есть шанс не запутаться в большом количестве данных.

4.2. Disallow
Директива используется при отключении страниц или разделов из списка адресов для сканирования. Она часто применяется для дублей, служебных URL, пагинации.
Disallow обязательно нужно совмещать с символом слеша. Если путь к адресу не зафиксирован, поисковые пауки проигнорируют правило. Поэтому лучше убедиться, что синтаксис корректен.
С директивой следует обращаться осторожно, поскольку есть риск, что в поисковую выдачу могут не попасть важные адреса. Перед сохранением изменений в файле лучше произвести дополнительный анализ.
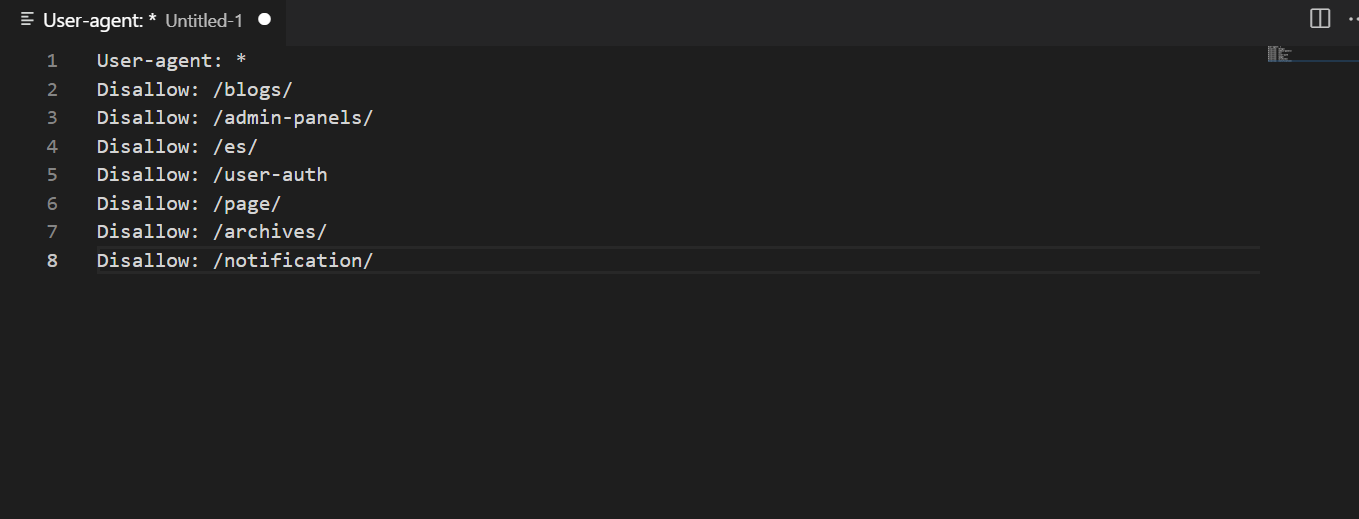
4.3. Allow
Одной из лучших практик для robots.txt является использование директивы Allow. Она позволяет сканировать страницы или целые разделы. Ее применяют в комбинации с Disallow, чтобы создать оптимальную структуру файла.
С Allow тоже нужно работать внимательно, чтобы в поисковую выдачу не попали служебные страницы и другие URL, которые размывают ссылочное внимание внутри проекта. Правильное использование слеша в адресах обеспечивает покрытие нужных страниц.
Когда в файле есть противоречивые правила по сканированию страниц, для Google решается количество символов. Выполнится самое длинное правило.

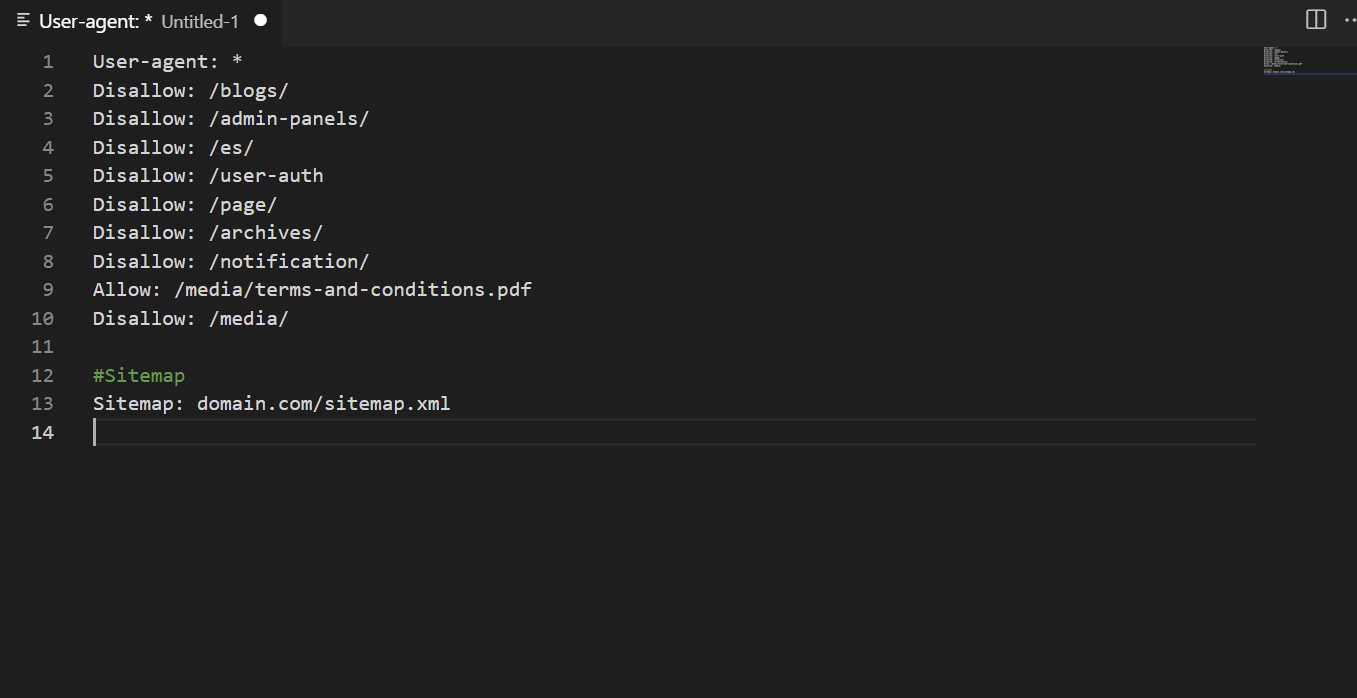
4.4. Sitemap
Директива считается необязательной, но опытные SEO специалисты рекомендуют ее использовать. Она указывает на расположение адреса с картой сайта. Ее нужно указывать в начале или конце документа.
Если карта добавлена через Google Search Console, можно не указывать URL еще и в robots, но вреда от этого не будет. В 99% публичных шаблонов robots.txt sitemap обязательно входит.
Сохранение правильного синтаксиса в файле обеспечивает корректное сканирование содержимого роботами поисковиков. А это положительно влияет на техническую оптимизацию и добавляет баллы к общему рейтингу проекта.
5. Неподдерживаемые директивы Robots.txt для Googlebot
В Сети можно увидеть устаревшие инструкции для robots, и новички совершают ошибку, опираясь на них. Это не помешает нормальной индексации и не повлечет за собой проблем с ранжированием страниц, но лучше адаптировать файл под правильный формат.
При просмотре технических файлов проектов с многолетней историей часто можно найти устаревшие директивы. Сами по себе они не несут вреда, поэтому игнорируются поисковыми работами. Но для идеальной оптимизации сайта от них лучше избавиться.
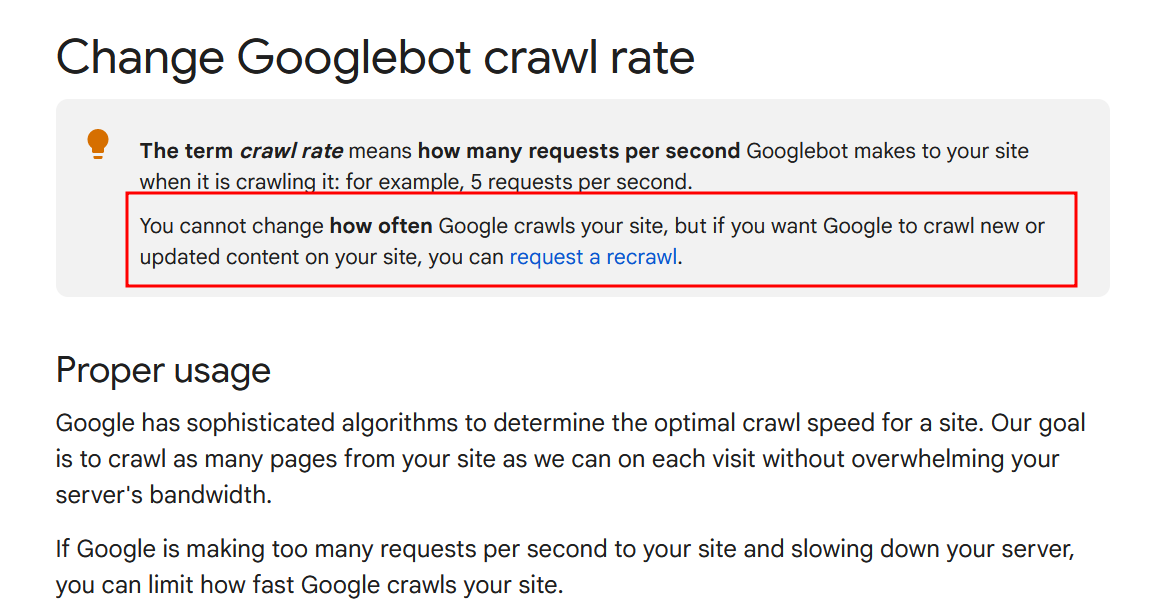
5.1. Crawl-delay
Ранее эта директива полностью соответствовала правильному формату robots.txt. Сейчас Google ее не поддерживает, поэтому нет смысла ограничивать скорость сканирования в файле — робот не будет ориентироваться на эти строки.
Bing все еще распознает директиву Crawl-delay, поэтому можно указать ее для подходящего пользователя-агента. Если трафика из Бинга нет, будет сложно найти повод для использования директивы.
5.2. Noindex
В справочном центре Google никогда не было упоминания о том, что можно запретить индексацию контента с помощью директивы Noindex. Но некоторые веб-мастера продолжают делать это в 2023 году.
В качестве альтернативы можно запретить сканирование с помощью Disallow и использовать технические инструменты для ограничения доступа на уровне сервера. Комбинация этих методов позволит получить желаемый результат.
5.3. Nofollow
Директива тоже не работает, как и аналогичный тег для ограничения передачи ссылочного веса. Пока нет эффективного способа для закрытия ссылок от распространения веса.
Создание файла robots.txt никак не помогает запретить индексацию ссылок. Роботы Google легко справляются даже с зашифрованными ссылками, которые не видны в исходном коде.
Среди устаревших директив можно встретить Host. Эта команда использовалась для обозначения главного зеркала сайта. Уже много лет ее заменой служит 301 редирект.
6. Как создать файл Robots.txt?
Robots — это обычный текстовый файл, который должен лежать в корне сайта. Его можно создать с помощью блокнота Windows или использовать стандартные инструменты файлового менеджера на сервере.
Следите за тем, чтобы файл имел правильное расширение. В противном случае роботы поисковых систем не смогут проанализировать содержимое, и в Search Console появится уведомление об ошибке доступа.
При необходимости можно использовать стандартный шаблон из открытых источников, но убедитесь, что в нем нет конфликтов. Только после этого можно использовать дефолтную структуру на постоянной основе.

6.1. Создайте файл с именем Robots.txt
Когда новички у SEO спрашивают, как создать файл robots.txt, ответ лежит на поверхности. Для этого не нужно устанавливать на компьютер специализированное программное обеспечение, достаточно «Блокнота».
Не забудьте сохранить изменения после каждого обновления документа. В стандартной программе нет автосохранения, поэтому часть данных может потеряться в процессе редактирования и придется приступать к работе сначала.
6.2. Добавьте правила в файл
Оптимальный путь для оформления правил в robots — это объединение пользователей-агентов и использование комментариев. Нет смысла указывать правила для одного робота в разных частях файла.
Добавляя правила, следите за тем, чтобы не было конфликтов. Они приводят к тому, что поисковые системы начинают действовать по своему усмотрению. Хотя даже если все указано правильно, нет гарантий выполнения директив.
6.3. Проверьте синтаксис
Правильный robots.txt для SEO — это файл, где нет синтаксических ошибок. Чаще всего новички допускают ошибки в написании директив. К примеру, вместо Disallow пишут Disalow.
Еще нужно внимательно следить за использованием слеша, звездочки и решетки. В этих символах легко запутаться и закрыть или открыть ненужные страницы для сканирования. Проверить синтаксис можно с помощью различных онлайн-сервисов.
6.4. Загрузите файл
После создания структуры файла и сохранения окончательного варианта на компьютере остается скачать его на сервер. Для этого подходит только корневой каталог.
Рекомендуем ограничить возможность перезаписи файла, так как после обновления CMS и плагинов синтаксис может пострадать. Это происходит не часто, но возникновение проблемы можно исключить только таким путём.
6.5. Протестируйте и исправьте ошибки, если это необходимо
На создании файла robots.txt работа с ним не завершается. Надо еще убедиться, что он не содержит ошибок. Закрыть задачу можно как вручную, так и с помощью онлайн-сканеров.
Например, можно воспользоваться инструментом, который неплохо справляется с анализом синтаксиса. В отчете отображаются информация об обнаруженных ошибках и статус доступности.

О найденных проблемах со сканированием и индексацией можно узнать в Google Search Console. Но лучше не допускать их появления и извлечь максимальную пользу от технической оптимизации.
7. Лучшие практики работы с Robots.txt
В работе со служебным файлом обычно нет ничего сложного, но если речь идет о продвижении больших проектов, то могут возникнуть проблемы с созданием идеального набора правил.
Оптимизация robots.txt требует времени и релевантного опыта. Онлайн-сканеры позволяют экономить ресурсы, но не закроют все потребности, поэтому от ручного анализа отказаться не получится.
Советы по эффективной работе с robots.txt будут полезны веб-мастерам с любым уровнем опыта. Иногда даже маленькая ошибка может разрушить большой объем проделанной работы, и ее нужно оперативно заметить.
7.1. Используйте новую строку для каждой директивы
Когда новички начинают разбираться в синтаксисе robots.txt, они часто допускают одну ошибку, а именно, пишут правила в одну строчку. Это составляет проблему для роботов-поисковиков.
Чтобы защититься от негативных последствий, нужно писать каждое правило с новой строчки. Это полезно как для спайдеров, так и для удобства навигации специалиста, обновляющего файл.
Плохо:
| User-agent:* Disallow: /admin-panel |
Хорошо:
| User-agent:* Disallow: /admin-panel |
7.2. Используйте каждый User-agent только один раз
Когда начинающие SEO-специалисты начинают интересоваться тем, что должно быть в robots.txt, мало кто вспоминает о необходимости правильного использования пользователей-агентов. Найти список популярных спайдеров не проблема, но это не все.
Если для одного работа создано 50 правил, их следует объединить. У роботов не будет проблем с самостоятельным объединением, но это лучше выполнить еще и с точки зрения удобства использования файла.
Плохо:
| User-agent: Googlebot Disallow: /admins-panel …. User-agent: Googlebot Allow: /blog |
Хорошо:
| User-agent: Googlebot Disallow: /admins-panel Allow: /blog |
7.3. Создавайте отдельные файлы Robots.txt для разных субдоменов
При продвижении больших проектов на тысячи страниц с десятками субдоменов нужно оптимизировать каждую директорию отдельно. Дело в том, что для поисковых систем субдомен — это новый сайт.
Robots.txt может быть шаблонным, но его нужно поместить в корневую директорию всех продвигаемых в поиске поддоменов. Это правило не относится к техническим субдоменам, закрытым от пользователей.
7.4. Будьте конкретны, чтобы минимизировать возможные ошибки
Очень часто у владельцев интернет-проектов возникают проблемы с закрытием доступа к страницам и разделам. Обычно это связано с неправильным использованием слеша и других знаков подстановки.
Практически каждый веб-мастер знает, что такое robots txt, но когда дело доходит до создания правил, многие допускают критические ошибки. И это может повлиять на индексацию и ранжирование.
К примеру, необходимо ограничить доступ к страницам с префиксом /es, так как директория находится в разработке. В этом случае на результат влияет правильное использование слеша.
Плохо:
| User-agent: * Disallow: /es |
Хорошо:
| User-agent: * Disallow: /es/ |
Во втором случае под ограничением находятся все страницы, относящиеся к соответствующей директории. А в первом случае могут возникнуть проблемы со всеми адресами, где есть конструкция es.
7.5. Используйте комментарии, чтобы объяснить свой файл Robots.txt людям
Пауки поисковиков игнорируют любые строки, где используется символ решетки. А веб-мастерам комментарии позволяют ориентироваться в структуре документа. Поэтому их однозначно следует использовать и уделить внимание при изучении, что такое robots.txt в SEO.
Отсутствие комментариев нельзя назвать плохой практикой, когда в документе 10–20 строк. А вот если их сотни, лучше написать подсказки для себя и SEO-специалистов, которые будут работать над проектом в будущем.

Лайфхаки по оптимизации robots также можно подсмотреть на авторитетных проектах, не имеющих проблем с поисковым трафиком. Большинство из них находятся в каталоге PRPosting. Для анализа достаточно собрать список из 5–10 ресурсов и посмотреть их версии файла.
Также в личном кабинете сервиса можно пообщаться с оптимизаторами при сделке по размещению ссылок. Так можно гармонично соединить внутреннюю и внешнюю оптимизацию.
8. Выводы
Многие знают, как найти robots.txt, но не все умеют правильно работать с файлом. Для усвоения базовых принципов оптимизации файла не требуется много времени, поэтому следует его потратить и постоянно совершенствовать знания.
FAQ
Что такое файл Robots.txt?
Это технический файл, содержащий правила сканирования страниц сайта. Поисковые роботы используют его, чтобы понять, какие разделы не являются приоритетными для индексации.
Как создать файл Robots.txt?
Это можно сделать с помощью Блокнота, FTP-менеджера или использовать специализированные сервисы. В каждом случае результат будет одинаковым.
Как найти Robots.txt?
В отличие от карты сайта, файл должен быть в корневой директории. Если он лежит в другом месте, смысла будет ноль.
Каков максимальный размер файла Robots.txt?
Приблизительное ограничение — 500 КБ. Вес зависит от количества строк, этот предел сложно перейти, если принимаются меры по оптимизации.







