
Czym jest plik Robots.txt i jak go poprawnie wykorzystywać?

Zazwyczaj zaraz po uruchomieniu witryny webmasterzy tworzą mapę witryny, zamykają strony serwisowe przed indeksowaniem i dodają metatagi. Czasami jednak zapominają o ważnych zadaniach, które należy wykonać w pierwszej kolejności.
Nawet początkujący wiedzą, czym jest robots.txt, ale nie wszyscy właściciele witryn poświęcają wystarczająco dużo uwagi na pracę z nim. W niektórych przypadkach plik jest generowany za pomocą wtyczek SEO, a webmaster zapomina o jego istnieniu. Może to prowadzić do problemów z indeksowaniem i rankingiem w przyszłości, więc lepiej mieć oko na ten plik.
1. Czym jest plik Robots.txt?
Robots.txt — to plik tekstowy, który zawiera reguły dla robotów indeksujących. One biorą go pod uwagę, gdy muszą indeksować strony i decydować, czy indeksować adres URL.
Plik ten powinien być postrzegany jako narzędzie zmniejszające obciążenie serwera projektu, a nie jako sposób na szybkie zablokowanie dostępu do stron serwisu. Działa to podobnie do tagu nofollow dla linków — wyszukiwarki mogą wziąć pod uwagę zasady, ale nie ma gwarancji, że to zadziała.
Wyszukiwarki zazwyczaj stosują się do istniejących wytycznych, ale w każdym przypadku decyzja podejmowana jest na podstawie kombinacji różnych czynników. Na przykład, gdy plik zawiera sprzeczne wiersze, aktywowane są dodatkowe algorytmy analizy.
Dobrze skomponowany plik robots.txt może być korzystny w SERP, ale jest to tylko jedna z tysięcy cegiełek potrzebnych do uzyskania dobrych pozycji w rankingach. Dlatego nie należy zbytnio przejmować się ciągłym aktualizowaniem pliku.
1.1. Jak konkretnie to działa?
Aby zrozumieć, jak działają roboty, należy zagłębić się w niuanse techniczne. Nauka nie zajmuje dużo czasu — podstawowe umiejętności można opanować w kilka godzin, korzystając z Pomocy Google dla Webmasterów.
Roboty wyszukiwarek wykonują dwie główne operacje: skanują zawartość stron i indeksują je. Robots.txt jest swego rodzaju mapą drogową. Pokazuje robotom indeksującym trasę, według której mogą skanować zasób. Nie można jednak z góry przewidzieć, czy roboty będą postępować zgodnie z podpowiedziami.
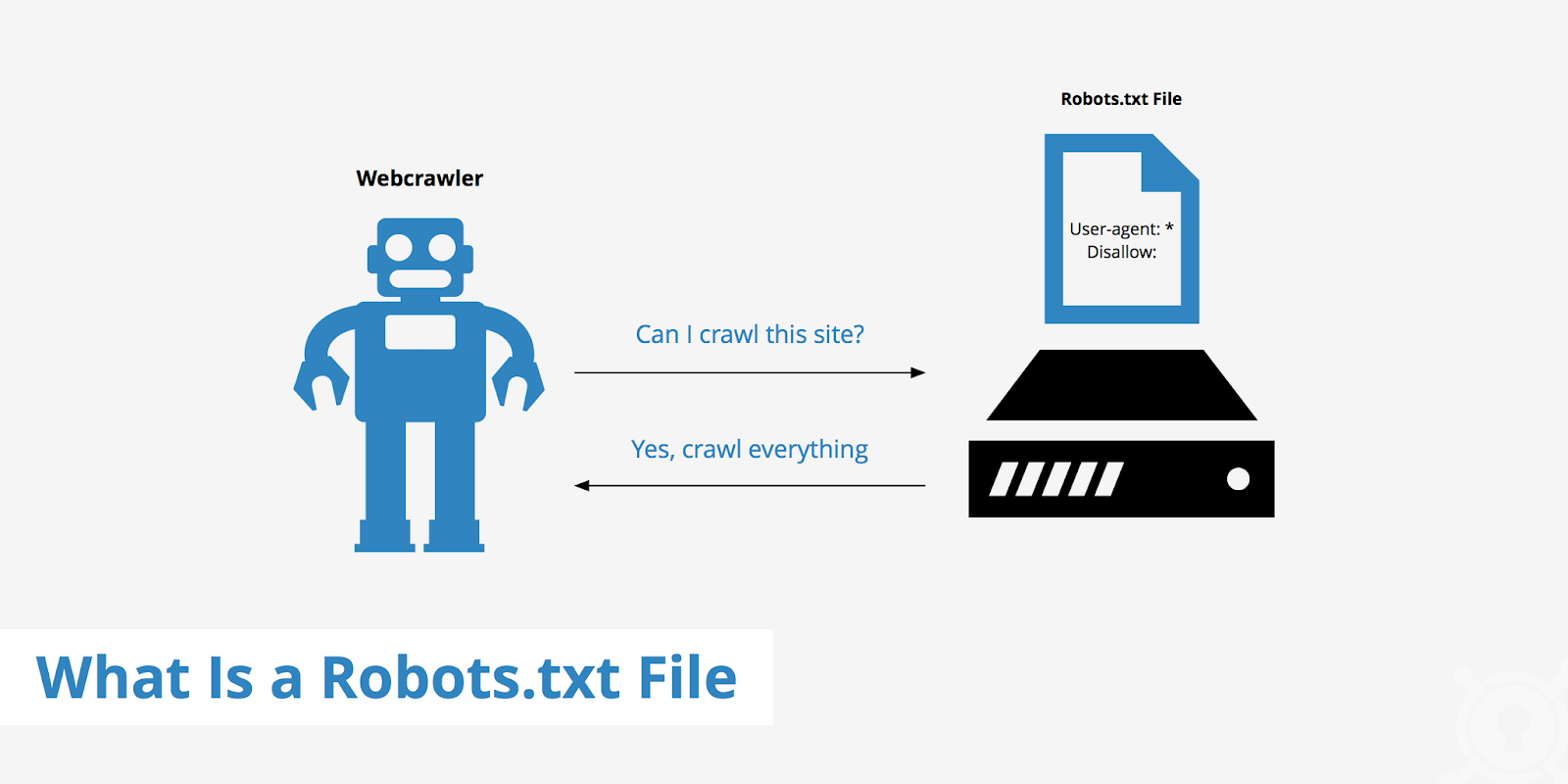
Zwykle przed indeksowaniem zasobów pająki wyszukiwarek analizują zawartość pliku robots.txt, aby zrozumieć, których stron właściciel projektu nie chce dodawać do indeksu. Mogą one przestrzegać zasad lub nie.
Roboty są często postrzegane jako skuteczne narzędzie do uniemożliwiania indeksowania, ale tak nie jest. Jeśli algorytmy wyszukiwarek uznają, że strona zawiera treści przydatne dla użytkowników, może ona zostać włączona do indeksu.
Należy również zrozumieć, że roboty indeksujące różnych serwisów pracują ze składnią pliku technicznego według unikalnego scenariusza. Dlatego, jeśli nie utworzysz własnych reguł dla konkretnego agenta użytkownika, w wynikach wyszukiwania mogą zostać uwzględnione dodatkowe adresy.
Aby w 100% zabezpieczyć się przed dodaniem strony do SERP, należy zablokować do niej dostęp za pomocą .htaccess lub innych narzędzi serwerowych. Wówczas adres URL nie musi być podawany w pliku robots.txt dla Google.
2. Dlaczego potrzebny jest plik robots.txt?
Istnieje opinia, że w 2023 roku nie ma potrzeby tworzenia pliku robots. W rzeczywistości jest to błędne stwierdzenie, ponieważ plik ten jest używany przez pająki wyszukiwania. Jest to zachęta by poświęcić czas na stworzenie dokumentu.
Robots.txt nie jest panaceum na zapobieganie indeksowaniu stron, ale zwykle dobrze radzi sobie z pokazywaniem wyszukiwarkom adresów, których nie warto omijać. Oszczędza to czas pająków i zasoby serwera.
Ponadto, jeśli dokument nie znajduje się w katalogu głównym, otrzymasz powiadomienie w Google Search Console. Nie ma w tym nic krytycznego, ale lepiej nie dawać algorytmom dodatkowego powodu do zwracania większej uwagi na projekt.
Nie ma potrzeby tworzenia pliku dla zasobów, które są promowane poza wyszukiwarkami. Dotyczy to SaaS i innych serwisów ze stałą grupą odbiorców. Decyzja o potrzebie wykonania zadań SEO jest podejmowana przez każdego webmastera indywidualnie, ale dodatkowe przejścia w żadnym wypadku nie będą zbędne.
2.1. Optymalizacja budżetu indeksowania
Budżet indeksowania — to limit indeksowania stron zasobu. Roboty Google indeksują adresy każdego projektu w inny sposób, więc nie można z góry określić, jak szybko będą indeksować wszystkie adresy URL.
Optymalizacja budżetu pod kątem indeksowania stron polega na zamknięciu rozdziałów serwisowych w pliku robots.txt dla Googlebota. Jeśli to zrobisz, pająki wyszukiwarki nie będą marnować zasobów na indeksowanie niepotrzebnych adresów, a indeksowanie ważnych adresów URL może się przyspieszyć.
Budżet indeksowania jest bardzo nieprzewidywalny, ale optymalizacja robots może pozytywnie wpłynąć na szybkość indeksowania stron przez pająki. Dlatego nie należy ignorować tego zadania.
2.2. Blokowanie zduplikowanych i niepublicznych stron
Zduplikowane strony powodują zmniejszenie masy referencyjnej i pogarszają pozycjonowanie stron. Na przykład, jeśli witryna ma 50 zduplikowanych adresów URL, które otrzymują ruch z wyszukiwarek, lepiej się ich pozbyć.
Istnieją również strony na każdej witrynie, które nie powinny być widoczne dla użytkowników: panel administracyjny, adres z prywatnymi statystykami itp. Lepiej zablokować do nich dostęp na poziomie serwera i dodatkowo wyszczególnić je w robots.

2.3. Zapobieganie indeksowaniu zasobów
Oprócz stron można użyć dyrektyw w pliku zasobu, aby zapobiec skanowaniu zawartości multimedialnej. Może to obejmować obrazy, pliki PDF, dokumenty Word i inne treści.
Zablokowanie w robots zwykle jest wystarczające, aby pliki z zawartością multimedialną nie pojawiały się w wynikach wyszukiwania. Jednak w niektórych przypadkach mogą pojawić się problemy. Jeśli algorytmy Google lub innych serwisów podejmą inną decyzję, jedynym sposobem na obejście tego problemu jest całkowite zablokowanie go na poziomie serwera.
Ograniczenie dostępu do obrazów lub skryptów w pliku zasobu zajmuje minimum czasu. Musisz znaleźć plik robots.txt i użyć specjalnych symboli wieloznacznych, aby upewnić się, że wszystkie dokumenty są objęte regułami.
Wysokiej jakości plik robots bez błędów — to bonus dla projektu. Jeśli konkurenci mają problemy z optymalizacją techniczną, może to być jeden ze sposobów na pokonanie ich w walce o ruch.
3. Jak znaleźć Robots.txt?
Plik można znaleźć w kilka sekund w katalogu głównym witryny pod adresem domain.com/robots.txt. Jeśli jest to subdomena, wystarczy zmienić tylko pierwszą część adresu.
Czasami występują problemy z ponownym zapisaniem pliku, więc lepiej wyłączyć tę operację przy pomocy managera FTP. Jeśli ręcznie wyłączysz możliwość zmiany treści, robots.txt dla SEO będzie działał z pełną wydajnością.
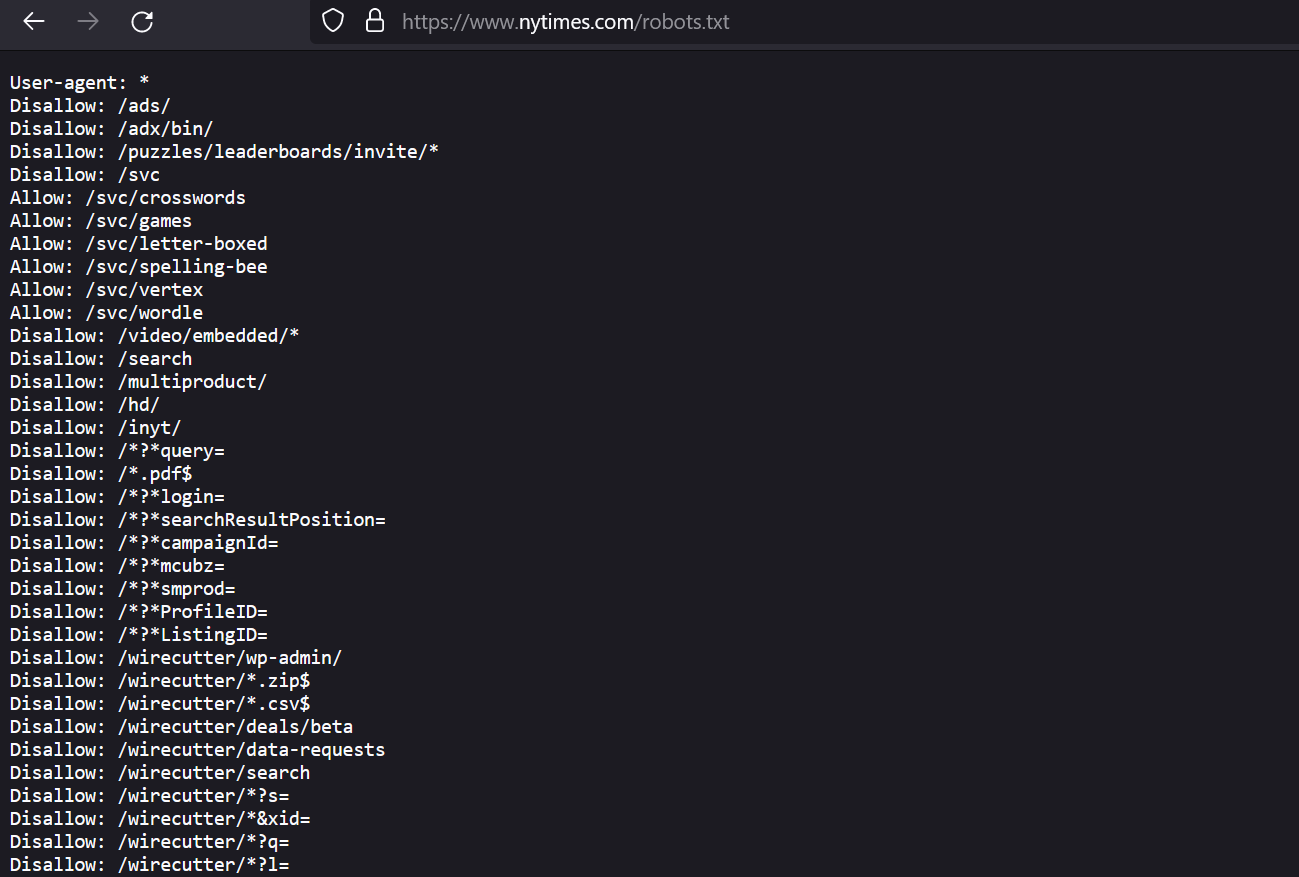
W popularnych systemach CMS wtyczki SEO mogą często wpływać na strukturę robots. W takim przypadku szablony utworzone przez webmastera nie są chronione przed zniknięciem. Jeśli plik zostanie nadpisany, właściciel witryny może tego nie zauważać przez długi czas.
Należy również upewnić się, że plik robots jest dostępny dla robotów. Aby to zrobić, należy użyć specjalistycznych narzędzi analitycznych. Jeśli odpowiedź serwera wynosi 200, nie będzie problemów z dostępem.
4. Składnia i obsługiwane dyrektywy
Dla początkujących SEO tworzenie robots może wydawać się trudnym zadaniem, ale w rzeczywistości w pracy z tym plikiem nie ma nic skomplikowanego. Jeśli wiesz, jakie operacje wykonuje symbol # lub wyrażenia regularne, możesz z nich korzystać bez żadnych problemów.
W pliku robots.txt występuje specyficzna składnia:
Ukośnik (/) pokazuje robotom, co dokładnie należy ukryć przed indeksowaniem. Może to być strona lub duża sekcja z tysiącami adresów.
Gwiazdka (*) pomaga podsumować adres URL w regule. Na przykład, jeśli chcesz zablokować wszystkie strony z plikiem pdf w adresie URL, musisz dodać gwiazdkę.
Znak dolara ($) jest dodawany na końcu adresu URL. Jest on zwykle używany do zabronienia skanowania plików lub stron z określonym rozszerzeniem.
Znak kratki (#) pomaga w nawigacji po pliku. Służy do oznaczania komentarzy, które wyszukiwarki ignorują.
Początkującym łatwiej zrozumieć składnię, gdy tylko stanie się jasne, czym jest plik robots.txt. Naukę można rozpocząć od dyrektyw, ale składnia jest również ważna.
Istnieją tylko 4 podstawowe dyrektywy, których należy się nauczyć. Możesz utworzyć te same reguły dla wszystkich agentów użytkownika i nie poświęcać dodatkowego czasu na każdą z nich osobno. Należy jednak pamiętać, że proces przeglądania strony jest inny dla każdego pająka.
4.1. User-agent
Wyszukiwarki i roboty indeksujące mają swoje własne user-agenty. Z ich pomocą serwer może zrozumieć, który robot odwiedził stronę. Następnie łatwo jest śledzić zachowanie konkretnego pająka w plikach.
User-agent jest używany w robots do wskazania, które reguły mają zastosowanie do konkretnego pająka. Gdy szablon jest taki sam dla wszystkich, w ciągu znaków używana jest gwiazdka.
Plik może zawierać co najmniej 50 dyrektyw z user-agent, ale lepiej jest stworzyć 3-5 oddzielnych list. I pamiętaj, aby dodać komentarze dla łatwej nawigacji. Wtedy jest szansa nie pogubić się w dużej ilości danych.

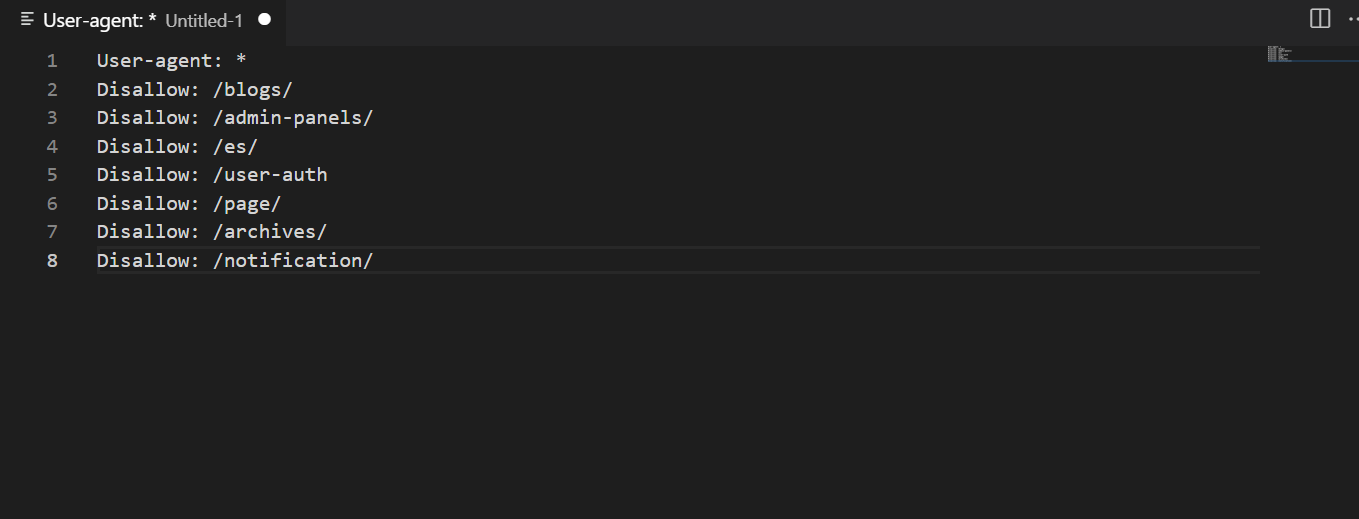
4.2. Disallow
Ta dyrektywa jest używana, gdy chcesz wykluczyć strony lub sekcje z listy adresów do indeksowania. Jest często stosowana w przypadku zduplikowanych stron, adresów URL serwisu i paginacji.
Disallow musi być połączona ze znakiem ukośnika. Jeśli ścieżka do adresu nie jest stała, pająki wyszukiwarek zignorują regułę. Dlatego lepiej upewnić się, że składnia jest poprawna.
Należy być ostrożnym z tą dyrektywą, ponieważ istnieje ryzyko, że ważne adresy mogą nie zostać uwzględnione w wynikach wyszukiwania. Lepiej przeprowadzić dodatkową analizę przed zapisaniem zmian w pliku.
4.3. Allow
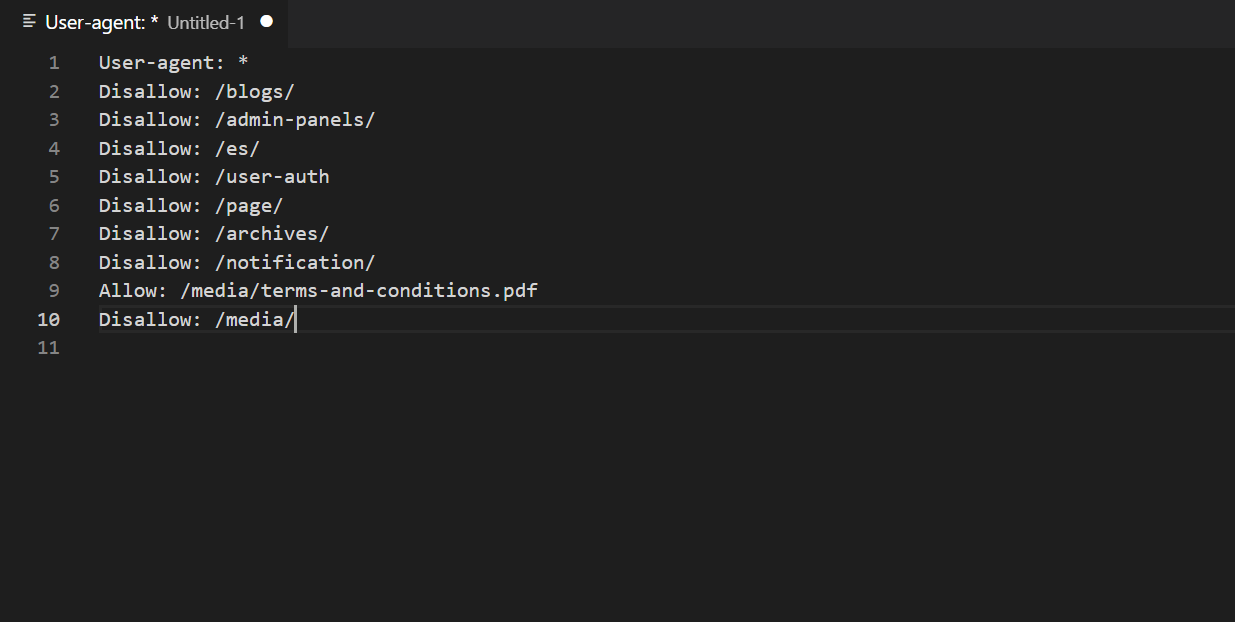
Jedną z najlepszych technik dla pliku robots.txt jest użycie dyrektywy Allow. Pozwala ona robotom na indeksowanie stron lub całych sekcji. Jest ona używana w połączeniu z Disallow w celu stworzenia optymalnej struktury pliku.
Należy również ostrożnie pracować z Allow, aby strony zasobu i inne adresy URL, które obniżają masę referencyjną w projekcie, nie dostały się do wyników wyszukiwania. Prawidłowe użycie ukośników w adresach zapewnia uwzględnienie właściwych stron.
Gdy istnieją sprzeczne reguły indeksowania stron w pliku, liczba znaków ma kluczowe znaczenie dla Google. Zastosowana zostanie najdłuższa reguła.
4.4. Sitemap
Ta dyrektywa jest uważana za opcjonalną, ale doświadczeni specjaliści SEO zalecają jej stosowanie. Wskazuje ona lokalizację adresu z mapą witryny. Powinna być umieszczona na początku lub na końcu dokumentu.
Jeśli mapa jest dodawana za pośrednictwem Google Search Console, można pominąć adres URL w pliku robots, ale to nie zaszkodzi. 99% publicznych szablonów robots.txt zawiera mapę witryny.
Zapisanie poprawnej składni w pliku zapewnia, że roboty wyszukiwarek poprawnie indeksują zawartość. Ma to pozytywny wpływ na optymalizację techniczną i dodaje punkty do ogólnego ratingu projektu.
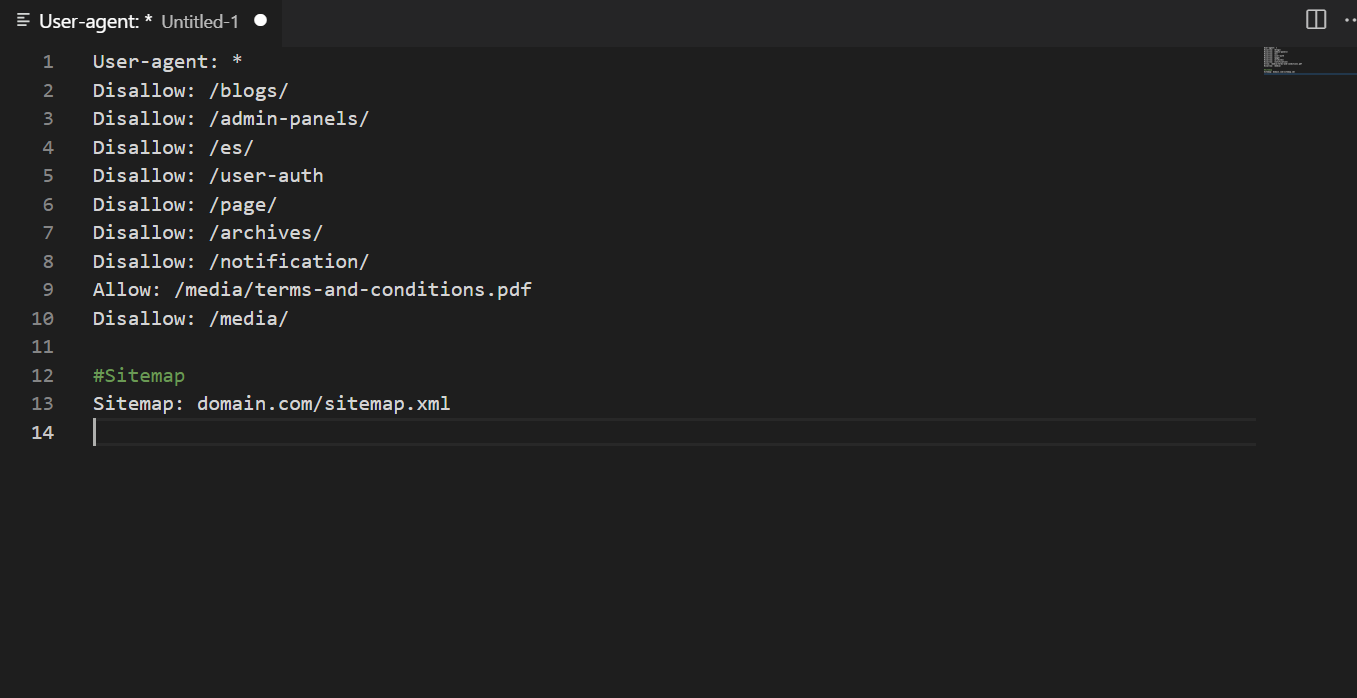
5. Nieobsługiwane dyrektywy robots.txt dla Googlebot
W sieci można zobaczyć nieaktualne instrukcje dla robots, a początkujący popełniają błędy na ich podstawie. Nie zakłóci to normalnego indeksowania i nie spowoduje problemów z rankingami stron, ale lepiej jest dostosować plik do prawidłowego formatu.
Jeśli przejrzysz pliki techniczne projektów o długiej historii, często znajdziesz nieaktualne wytyczne. Same w sobie nie są one szkodliwe, więc są ignorowane przez roboty wyszukiwarek. Jednak dla doskonałej optymalizacji witryny lepiej się ich pozbyć.
5.1. Crawl-delay
Dyrektywa ta była kiedyś w pełni zgodna z prawidłowym formatem robots.txt. Obecnie Google jej nie obsługuje, więc nie ma sensu ograniczać prędkości indeksowania w pliku — robot nie skupi się na tych liniach.
Bing nadal rozpoznaje dyrektywę Crawl-delay, więc można ją określić dla odpowiedniego agenta użytkownika. Jeśli nie ma ruchu z Bing, trudno będzie znaleźć powód do użycia dyrektywy.
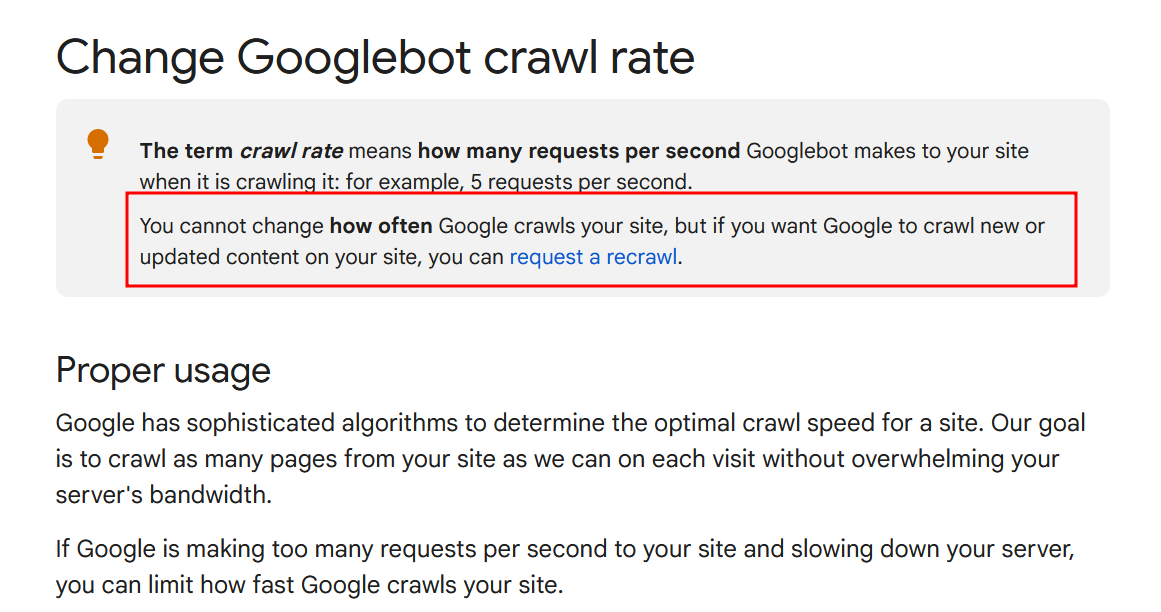
5.2. Noindex
Centrum pomocy Google nigdy nie wspomniało, że możliwe jest zapobieganie indeksowaniu treści za pomocą dyrektywy Noindex. Jednak niektórzy webmasterzy nadal to robią w 2023 roku.
Alternatywnie można uniemożliwić indeksowanie za pomocą Disallow i użyć narzędzi technicznych do ograniczenia dostępu na poziomie serwera. Połączenie tych metod pomoże uzyskać pożądany rezultat.
5.3. Nofollow
Ta dyrektywa również nie działa, podobnie jak podobny tag ograniczający przenoszenie link juice. Obecnie nie ma skutecznego sposobu na zamknięcie linków rozprzestrzeniających sok z linków.
Utworzenie pliku robots.txt nie pomaga zakazać indeksowania linków. Roboty indeksujące Google z łatwością radzą sobie z zaszyfrowanymi linkami, które nie są widoczne w kodzie źródłowym.
Wśród przestarzałych dyrektyw można znaleźć również Host. Polecenie to służyło do wskazania głównego serwera lustrzanego strony. Od wielu lat jest ona zastępowana przez przekierowanie 301.
6. Jak utworzyć plik robots.txt?
Robots — to zwykły plik tekstowy, który powinien znajdować się w katalogu głównym witryny. Można go utworzyć za pomocą Notatnika w systemie Windows lub użyć standardowych narzędzi managera plików na serwerze.
Upewnij się, że plik ma prawidłowe rozszerzenie. W przeciwnym razie roboty indeksujące nie będą w stanie przeanalizować jego zawartości, a w Search Console pojawi się powiadomienie o błędzie dostępu.
W razie potrzeby możesz użyć standardowego szablonu z otwartych źródeł, ale upewnij się, że on nie ma konfliktów. Tylko wtedy można na stałe korzystać z domyślnej struktury.
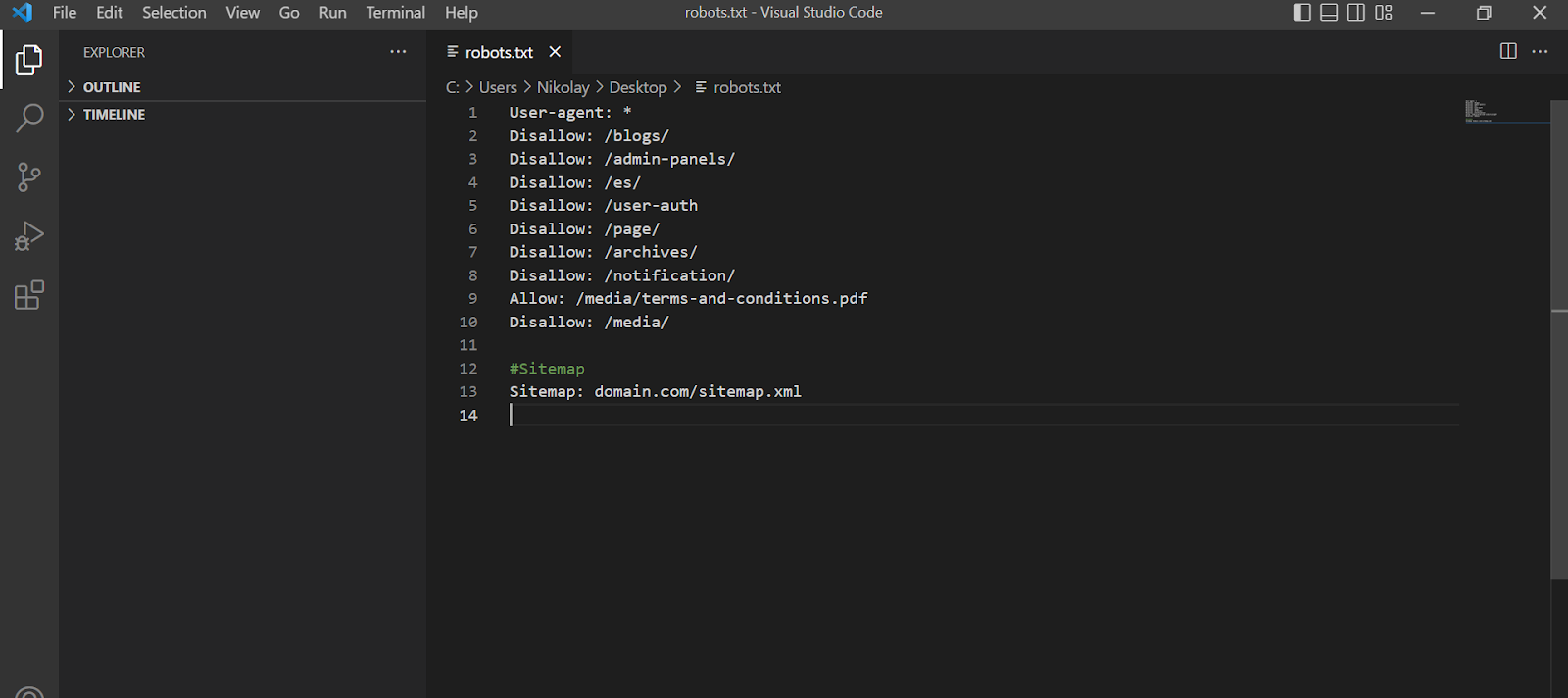
6.1. Utwórz plik o nazwie Robots.txt
Kiedy początkujący SEO pytają, jak utworzyć plik robots.txt, odpowiedź leży na powierzchni. Nie musisz instalować specjalistycznego oprogramowania na swoim komputerze, wystarczy Notatnik.
Nie zapomnij zapisać zmian po każdej aktualizacji dokumentu. Standardowe oprogramowanie nie ma funkcji automatycznego zapisywania, więc niektóre dane mogą zostać utracone podczas procesu edycji i będziesz musiał zacząć od nowa.
6.2. Dodaj do pliku reguły
Prawidłowym sposobem pisania reguł w robots jest łączenie user-agents i używanie komentarzy. Nie ma sensu określać reguł dla jednego robota w różnych częściach pliku.
Podczas dodawania reguł należy upewnić się, że nie ma konfliktów. Powodują one, że wyszukiwarki działają według własnego uznania. Jednak nawet jeśli wszystko zostanie określone poprawnie, nie ma gwarancji, że dyrektywy zostaną wykonane.
6.3. Sprawdź składnię
Prawidłowy robots.txt dla SEO — to plik, który nie zawiera żadnych błędów składniowych. Najczęściej początkujący popełniają błędy w napisaniu dyrektyw. Na przykład zamiast Disallow piszą Disalow.
Należy również uważnie monitorować użycie ukośników, gwiazdek i kratek. Łatwo jest pomylić te symbole i zamknąć lub otworzyć niepotrzebne strony do skanowania. Składnię można sprawdzić za pomocą różnych serwisów online.
6.4. Prześlij plik
Po utworzeniu struktury pliku i zapisaniu ostatecznej wersji na komputerze należy przesłać ją na serwer. Do tego celu nadaje się tylko katalog główny.
Zalecamy ograniczenie możliwości nadpisania pliku, ponieważ składnia może ulec zmianie po aktualizacji CMS i wtyczek. Nie zdarza się to często, ale jest to jedyny sposób, aby zapobiec wystąpieniu problemu.
6.5. Przetestuj i popraw błędy, jeśli to konieczne
Praca z plikiem robots.txt nie kończy się na jego utworzeniu. Następnie musisz upewnić się, że nie nie zawiera on żadnych błędów. Zadanie to można zrobić ręcznie lub za pomocą skanerów online.
Można na przykład użyć narzędzia, które dobrze radzi sobie z analizowaniem składni. Raport wyświetla informacje o znalezionych błędach i statusie dostępności.
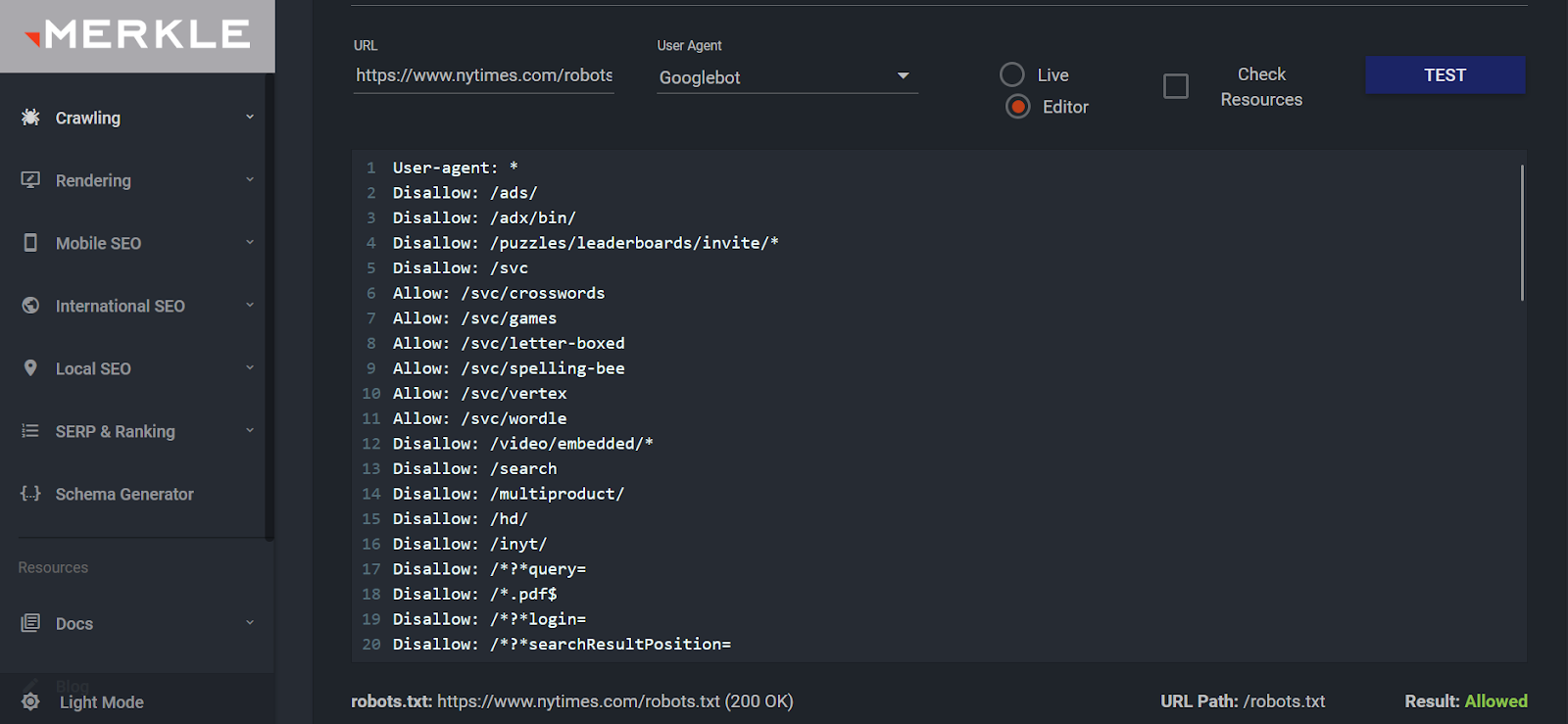
Możesz dowiedzieć się o problemach z indeksowaniem w Google Search Console. Lepiej jednak zapobiegać ich występowaniu i czerpać jak najwięcej korzyści z optymalizacji technicznej.
7. Najlepsze praktyki pracy z plikiem robots.txt
Zwykle nie ma nic skomplikowanego w pracy z plikiem, ale jeśli chodzi o promowanie dużych projektów, możesz mieć problem z utworzeniem idealnego zestawu reguł.
Optymalizacja Robots.txt wymaga czasu i odpowiedniego doświadczenia. Skanery online mogą zaoszczędzić środki, ale nie zaspokoją wszystkich potrzeb. Dlatego nie można zrezygnować z ręcznej analizy.
Wskazówki dotyczące skutecznej pracy z robots.txt będą przydatne dla webmasterów na wszystkich poziomach doświadczenia. Czasami nawet mały błąd może zrujnować dużą ilość wykonanej pracy i należy go szybko zauważyć.
7.1. Używaj nowej linii dla każdej dyrektywy
Kiedy początkujący zaczynają rozumieć składnię pliku robots.txt, często popełniają jeden błąd, a mianowicie zapisują reguły w jednej linii. Jest to problem dla robotów indeksujących wyszukiwarek.
Aby uchronić się przed negatywnymi konsekwencjami, należy zapisać każdą regułę w nowej linii. Jest to przydatne zarówno dla pająków, jak i dla łatwości nawigacji specjalisty, który będzie aktualizował plik.
Źle:
User-agent:* Disallow: /admin-panel
Dobrze:
User-agent:* Disallow
Disallow: /admin-panel
7.2. Używaj każdy User-agent tylko raz
Kiedy początkujący specjaliści SEO interesują się tym, co powinno znajdować się w pliku robots.txt, niewiele osób wspomina o konieczności poprawnego używania user-agentów. Nie jest problemem znalezienie listy popularnych pająków, ale tego nie wystarczy.
Jeśli masz 50 reguł dla jednego robota, warto je połączyć. Roboty wyszukiwarek nie będą miały problemu z połączeniem ich samodzielnie, ale lepiej zrobić to z punktu widzenia użyteczności pliku.
Źle:
User-agent: Googlebot
Disallow: /admins-panel
….
User-agent: Googlebot
Allow: /blog
Allow:
Dobrze:
User-agent: Googlebot
Disallow: /admins-panel
Allow: /blog
7.3 Twórz oddzielne pliki robots.txt dla różnych subdomen
Podczas promowania dużych projektów z tysiącami stron i dziesiątkami subdomen, należy zoptymalizować każdy katalog osobno. Faktem jest, że dla wyszukiwarek subdomena jest nową witryną.
Robots.txt może być szablonowym, ale musi być umieszczony w katalogu głównym wszystkich subdomen, które są promowane w wyszukiwarkach. Zasada ta nie dotyczy subdomen technicznych, które są zamknięte dla użytkowników.
7.4. Bądź konkretny, aby zminimalizować możliwe błędy
Nierzadko właściciele witryn mają problemy z zamykaniem dostępu do stron i sekcji. Jest to zwykle spowodowane nieprawidłowym użyciem ukośników i innych symboli wieloznacznych.
Prawie każdy webmaster wie, czym jest robots txt, ale jeśli chodzi o tworzenie reguł, wielu popełnia krytyczne błędy. A to może mieć wpływ na indeksowanie i promowanie.
Na przykład, musisz ograniczyć dostęp do stron z prefiksem /es, ponieważ katalog jest w fazie rozwoju. W tym przypadku na wynik ma wpływ prawidłowe użycie ukośnika.
Źle:
User-agent: *.
Disallow: /es
Dobrze:
User-agent: *
Disallow: /es/.
W drugim przypadku wszystkie strony należące do odpowiedniego katalogu są ograniczone. W pierwszym przypadku mogą wystąpić problemy ze wszystkimi adresami zawierającymi konstrukcję es.
7.5. Używaj komentarzy, aby wyjaśnić ludziom swój plik robots.txt
Pająki wyszukiwarek ignorują wszystkie linie, które używają symbolu kraty. Dla webmasterów komentarze pomagają w poruszaniu się po strukturze dokumentu. Dlatego zdecydowanie należy z nich korzystać i zwracać na nie uwagę podczas nauki, czym jest robots.txt w SEO.
Brak komentarzy nie można nazwać złą praktyką, gdyż w dokumencie znajduje się 10-20 linii. Natomiast jeśli są ich setki, lepiej napisać wskazówki dla siebie oraz innych specjalistów SEO, którzy będą pracować nad projektem w przyszłości.
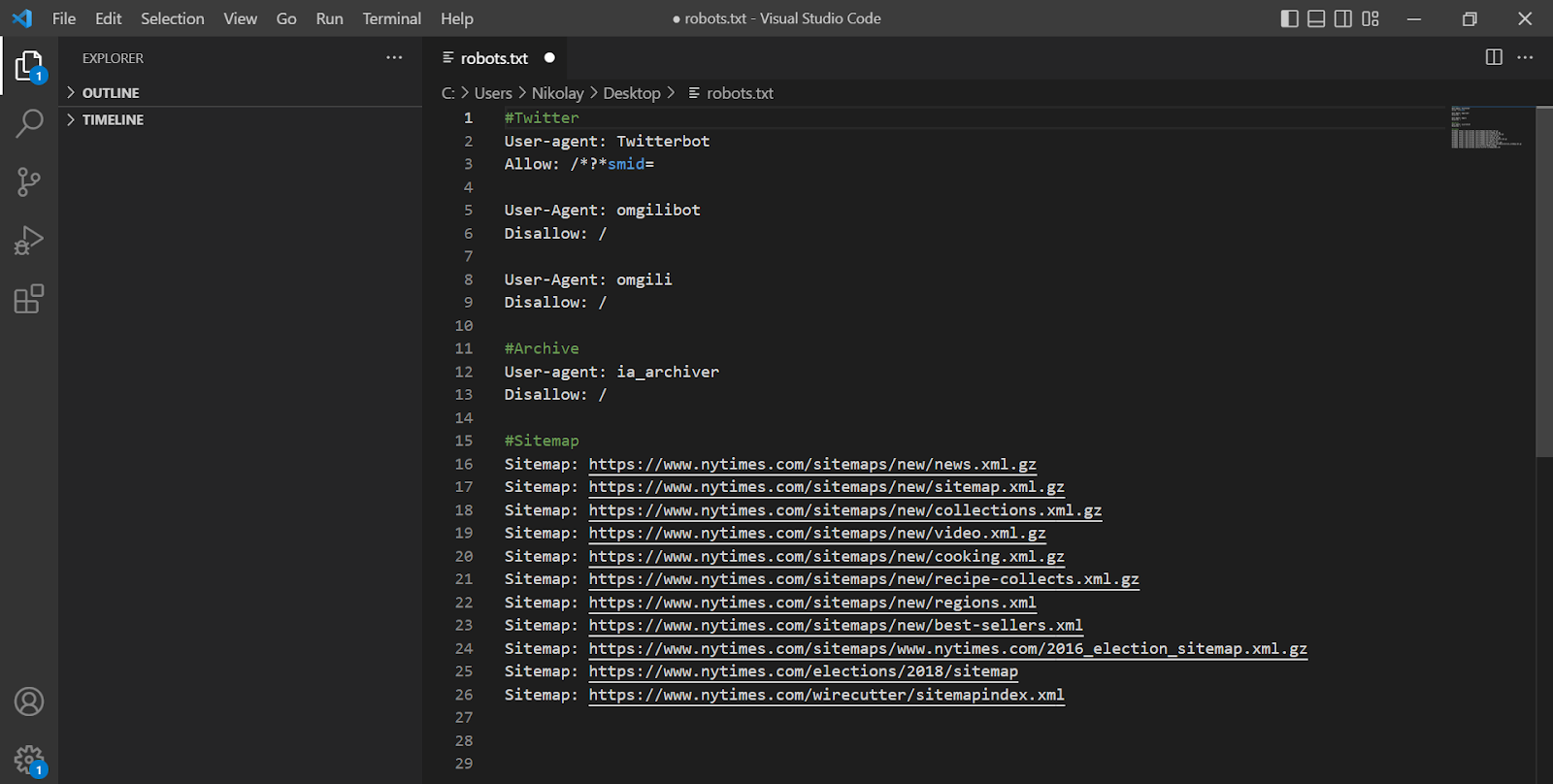
Life hacki do optymalizacji robots można również znaleźć w renomowanych projektach, które nie mają problemów z ruchem. Większość z nich znajduje się w katalogu PRPosting. Aby je przeanalizować, wystarczy zebrać listę 5-10 zasobów i przyjrzeć się ich wersjom plików.
Możesz również komunikować się z optymalizatorami na swoim koncie osobistym podczas transakcji umieszczania linków. W ten sposób można harmonijnie połączyć optymalizację wewnętrzną i zewnętrzną.
8. Podsumowanie
Wiele osób wie, jak znaleźć plik robots.txt, ale nie wszyscy wiedzą, jak poprawnie z nim pracować. Poznanie podstawowych zasad optymalizacji pliku nie zajmuje dużo czasu, dlatego warto go poświęcić i stale pogłębiać swoją wiedzę.
Czym jest plik robots.txt?
Jest to plik techniczny, który zawiera zasady indeksowania stron internetowych. Wyszukiwarki używają go, aby zrozumieć, które rozdziały nie są priorytetem do indeksowania.
Jak utworzyć plik robots.txt?
Można to zrobić za pomocą Notatnika, managera FTP lub skorzystać ze specjalistycznych serwisów. W każdym przypadku wynik będzie taki sam.
Jak znaleźć plik robots.txt?
W przeciwieństwie do mapy witryny, plik musi znajdować się w katalogu głównym. Jeśli znajduje się w innym miejscu, będzie bezużyteczny.
Jaki jest maksymalny rozmiar pliku Robots.txt?
Przybliżony limit — to 500 KB. Waga zależy od liczby wierszy i trudno jest przekroczyć ten limit, jeśli zostaną podjęte działania optymalizacyjne.






